
Tipos de modelos de bloques más comunes encontrados en el industria minera: Datamine.
Los tipos de modelos de bloques más comunes que se encuentran en la industria minera son Datamine, Vulcan, Surpac, Micromine y MineSight.
Los modelos de formato Datamine son actualmente el mejor formato para usar, ya que son compatibles con comandos extensos para interrogación y manipulación. Dado esto, hemos discutido este formato de archivo más extensamente que los otros formatos.
El formato Datamine estan disponibles públicamente y, por lo tanto, eran bien conocidos. Por lo tanto, muchos de los paquetes de modelado geológico admiten la exportación de sus modelos como modelos de Datamine. Otros formatos de modelos han tenido que determinarse mediante una interpretación juiciosa de prueba y error de lo que creemos que es la forma en que almacenan sus datos.
MB TIPO DATAMINE
Los modelos de bloques de Datamine se reconocerán por su sufijo: *.dm.
Hay dos limitaciones principales de los archivos Datamine que deben entenderse:
(a) Los archivos Datamine solo admiten ocho caracteres como nombres de campo.
(b) Los archivos de Datamine están limitados a un total de 256 campos (si están en el formato de precisión extendido predeterminado).
El formato Datamine tiene sus raíces en una larga historia. Datamine se fundó en 1981 y utiliza el sistema de gestión de base de datos relacional G-EXEC desarrollado por el Servicio Geológico Británico durante la década de 1970.
Los archivos Datamine son archivos de acceso aleatorio almacenados como tablas planas sin ninguna relación jerárquica o de red implícita. La estructura del modelo se define en un archivo de “prototipo de modelo” y el contexto espacial de cada bloque se almacena como parte del registro de cada bloque mediante posicionamiento implícito, lo que ahorra espacio de almacenamiento y tiempo de procesamiento. Esto se hace utilizando el código de indexación IJK (ver Figura 11 y Figura 12), lo que permite un acceso rápido por parte del programa de computadora a cualquier parte del modelo.
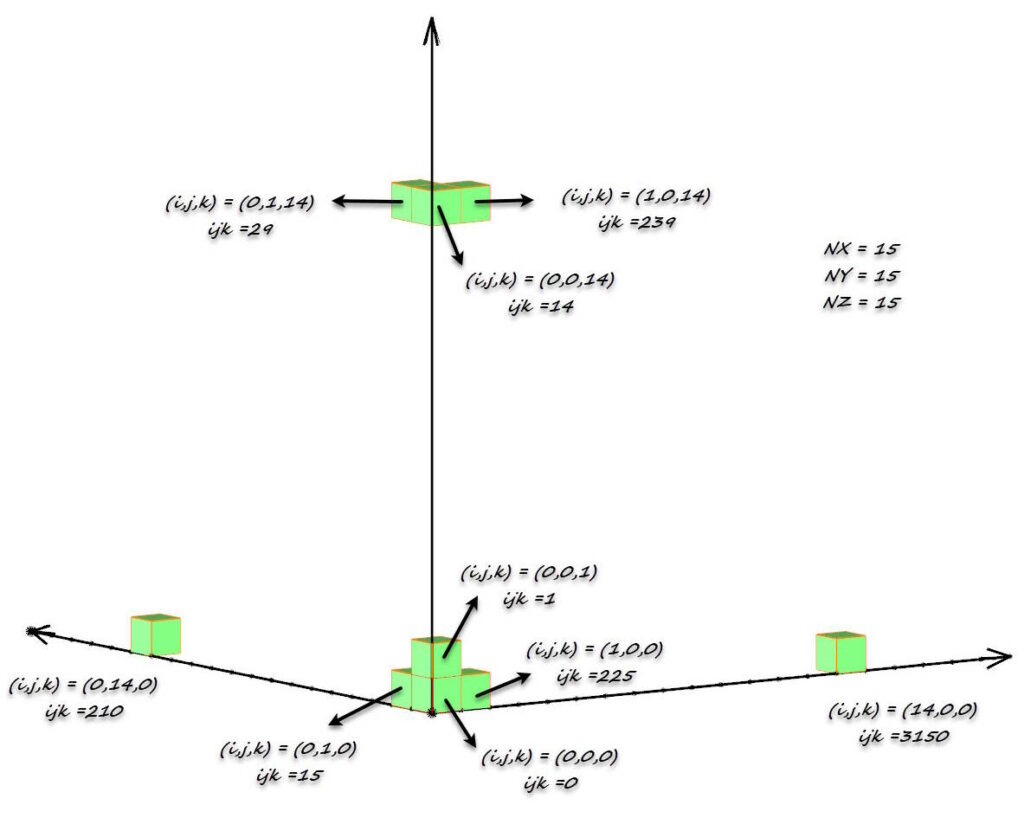
Algunas matemáticas relacionadas con el código IJK son:
IJK = NZ × NY × I + NZ × J + K
El IJK también se puede determinar a partir del sistema de coordenadas del modelo:
I = REDONDO[ (Xc-XParentINC/2)/XParentINC]*XParentINC – XmORIG)/XParentINC
J = ROUND[ (Yc-YParentINC/2)/YParentINC]*YParentINC –YmORIG)/YParentINC
K = REDONDO[ (Zc-ZParentINC/2)/ZParentINC]*ZParentINC –
ZmORIG)/ZParentINC
Donde XParentINC, YParentINC y ZParentINC son los X, Y y tamaños Z de los bloques principales (a cualquier subcelda).
La estructura del prototipo del modelo utiliza los campos que se muestran en la siguiente tabla.
| Campos | Descripción |
| XMORIG, YMORIG, ZMORIG | Origen XYZ del modelo. Datamine establece el origen con respecto a la esquina de la primera celda principal y NO su centroide. |
| XINC, YINC, ZINC | Dimensiones de la celda XYZ (incrementos). |
| NX, NY, NZ | Número de celdas principales del modelo en XYZ. Datamine permite un valor de uno para el modelado de costuras. El número de celdas, en combinación con el tamaño principal de la celda, define la extensión de las dimensiones del modelo. |
| XC, YC, ZC | Coordenadas del centro de la celda XYZ. |
| IJK | Código generado y utilizado por Datamine para identificar de manera única cada posición de celda principal dentro del modelo. Las subceldas que se encuentran dentro de la misma celda principal tendrán el mismo valor IJK. |
| I | Posición del bloque (celda) a lo largo del eje x (cero “0” para la primera posición, y aumentando por valores enteros). |
| J | Posición del bloque (celda) a lo largo del eje y (cero “0” para la primera posición, y aumentando por valores enteros). |
| K | Posición del bloque (celda) a lo largo del eje z (cero “0” para la primera posición, y aumentando por valores enteros). |

VERSIONES DEL FORMATO DATAMINE
Hay dos versiones del formato DM: precisión simple (SP) y precisión extendida (EP).
El formato DM de precisión simple original se basaba en “páginas” de 2048 bytes. (Estos son los registros de Fortran de palabras de 512 × 4 bytes). La primera página contenía la definición de datos mientras que las páginas siguientes contenían los registros de datos.
Hay dos tipos de datos: texto o alfa (“A”) y números de punto flotante (“N”).
Los elementos enteros en la página de definición de datos se almacenan como valores Fortran REAL4 o REAL8 en los formatos de precisión simple y extendida respectivamente.
Hay algunos códigos numéricos especiales que se utilizan dentro de los datos.
-1.0 E30 = “abajo”; se utiliza como código de datos faltantes para campos numéricos, también conocido como “valor nulo”. (Para los campos de texto, los datos que faltan son simplemente todos los espacios en blanco).
+1.0 E30 = “superior”; y se usa si se necesita una representación de “infinito”.
+1.0 E-30 = “TR” o “DL”; se utiliza si se requiere para representar un valor de ensayo de “traza” o “por debajo del límite de detección”.
Todos los datos de texto se mantienen en variables REALES, no en el tipo CARÁCTER de Fortran, aunque el formato almacenado es idéntico. Esto permite el uso de una matriz REAL simple para contener un búfer de página completo y otra matriz REAL para contener la totalidad de cada registro lógico para escritura o lectura. Este concepto se originó en el sistema G-EXEC del Servicio Geológico Británico en 1972 y fue la clave de la generalidad de Datamine, en lugar de tener que predefinir formatos de datos específicos para cada combinación diferente de texto y campos numéricos.
El formato de archivo Datamine de “precisión extendida” (EP) tiene páginas dos veces más grandes que el formato de archivo de “precisión simple” (4096 bytes de longitud) y la estructura de la página simplemente se asigna a palabras de 8 bytes en lugar de palabras de 4 bytes.
El formato de archivo Datamine de “precisión simple” es efectivamente un formato heredado y, con suerte, ahora no se encontrará con frecuencia. Estos archivos solo pueden tener 64 campos, mientras que los archivos de “doble precisión” pueden tener 256 campos.
El formato de archivo EP Datamine permite el Fortran REAL*8 completo (o DOUBLE PRECISION), pero para los datos de texto solo se utilizan los primeros cuatro bytes de cada palabra de doble precisión. Por lo tanto, la estructura de archivos EP es ineficiente en términos de almacenamiento de datos para archivos que tienen cantidades significativas de datos de texto.
Los modelos de bloques de Datamine tienen dos “niveles” de bloques: bloques principales y bloques secundarios (subbloques o subceldas). Cuando se crea un modelo de Datamine, el usuario especifica el tamaño del bloque principal, que será consistente durante la vida útil del modelo.
Durante el proceso de creación de un modelo de bloques de Datamine, los subbloques se crean a lo largo de los límites para que un bloque principal pueda tener cualquier cantidad de bloques secundarios, y pueden ser de cualquier tamaño. Es posible que cada bloque principal tenga un número diferente de bloques secundarios.
DATAMINE – UNICODE
Los modelos de bloque Unicode de Datamine se reconocerán por su sufijo: *.dmu.
Una limitación importante con el formato de archivo Datamine es que almacena todo el texto en formato ASCII, que se desmorona cuando intenta trabajar en un lenguaje simbólico como ruso, polaco, japonés, chino, etc.
Tenga en cuenta que un modelo de bloque *.dmu tiene las siguientes características:
- No hay límite en el tamaño del nombre del campo (solía tener ocho caracteres, ahora puede ser cualquier cosa).
- Hay soporte para cualquier idioma, codificado directamente en el archivo.
- Todavía hay un límite estricto de 256 campos, pero ahora su campo de texto solo cuenta para uno de esos campos. Anteriormente, si su columna de texto tenía un ancho de 20, contaría como cinco campos, por lo que ahora puede comprimir más campos de manera efectiva si está usando texto.
- Hay disponibles longitudes de texto variables. Si tuviera una columna con AAAA y AAAAAAAA, necesitaría definir de antemano que la columna tiene ocho caracteres. Ahora, no le importa el número de caracteres (máximo o mínimo) que haya en una columna.
La recomendación es que probablemente no debería usar archivos *.dmu a menos que realmente tenga que hacerlo. Hay muchos más usuarios que usan archivos *.dm, por lo que es más probable encontrar y corregir cualquier error de software relacionado con los modelos de bloques para los archivos *.dm que para los archivos *.dmu.
Proxima entrega: Modelo de bloques en Surpac, Vulcan, Minesight y Micromine.
Etiqueta:.dm, Datamine, Geologia, leapfrog, modelamiento, modelo de bloques, Surpac, vulcan




1 Comentario