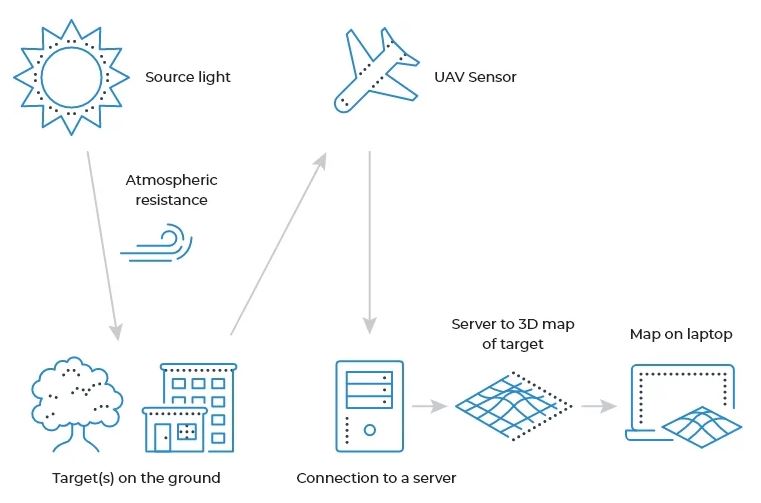
Una herramienta popular en la teledetección, la fotogrametría procesa imágenes recolectadas usando sensores montados desde UAV, aviones tripulados o satélites para crear imágenes a gran escala.
Estas imágenes, llamadas ortofotos u ortoimágenes, se fijan a una ubicación mediante el posicionamiento GPS y se normalizan mediante metadatos sobre condiciones ambientales como la humedad, la hora, la fecha y más. Esta información se envía a los servidores para su recopilación y almacenamiento.
Una vez recopiladas, las ortoimágenes se pueden introducir en un software avanzado de cartografía y topografía para crear representaciones y mapas 3D medibles. La comparación de las diferencias en los datos a lo largo del tiempo puede detectar variaciones en la composición química, la hidratación y la humedad, la temperatura y otros factores ambientales, todo sin poner las botas en el suelo.
Esta vista de ojos en el cielo es increíblemente valiosa para evaluar grandes propiedades y examinar la infraestructura remota sin una inversión sustancial en equipos tripulados.
Fotogrametría y espectro electromagnético
Las variaciones simples en la luz visible pueden ofrecer muchas pistas sobre los objetos a continuación.
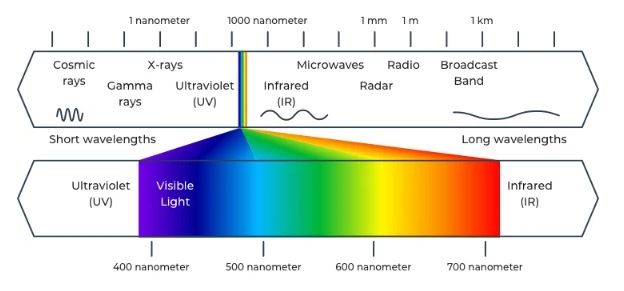
Los sensores de fotogrametría recolectan luz del espectro de luz visible (y en algunos casos, más allá de él) para crear una imagen de paisajes, infraestructura vital o cualquier objeto o escena 3D. Agregue metadatos ambientales a imágenes de alta resolución y los investigadores pueden hacer hipótesis asombrosamente precisas sobre las condiciones del mundo real.
La luz hace más que crear una bonita imagen para el mapa. Las rocas, la vegetación y los objetos manufacturados tienen huellas digitales espectrales únicas que pueden usarse para ayudar a identificar su densidad, composición química y más.
Armados con tecnología de detección remota de alta potencia, los investigadores pueden usar la fotogrametría aérea para recopilar evidencia de otros espectros (como la radiación ultravioleta o infrarroja) junto con la luz visible para sacar conclusiones más profundas sobre el medio ambiente que se encuentra debajo.
¿Qué es LiDAR?
Inspirado en el sonar y la ecolocalización, LiDAR utiliza documentación láser de nube de puntos para crear un mapa detallado punto por punto de la posición de un objeto en el espacio.
Usado comúnmente para generar conciencia espacial en realidad aumentada, software de conducción automatizada y topografía avanzada, LiDAR puede analizar grandes parcelas de tierra en busca de densidad, topografía y vegetación. Si bien LiDAR puede producir mediciones increíblemente precisas, no crea una ortoimagen y, por lo tanto, carece de datos ambientales críticos.
Lograr claridad: captura de imágenes y creación de un plan de vuelo con drones
Para obtener los mejores resultados, un vuelo de captura de imágenes debe planificarse cuidadosamente y ejecutarse correctamente. Factores como la altitud, la humedad, la velocidad y la temperatura de la luz afectarán la calidad de las imágenes (y, por lo tanto, la calidad del mapa ortomosaico terminado).
En un escenario ideal, el plan de vuelo de un dron será uniforme en todos los sentidos posibles. Las imágenes se recopilarán desde la misma elevación sobre un objeto o paisaje objetivo y se tomarán a la misma velocidad con condiciones atmosféricas constantes. Cualquier desviación en la trayectoria de vuelo y en el proceso de captura de imágenes debe ser lo suficientemente pequeña como para normalizarse durante el procesamiento antes de renderizar el modelo.
Problemas comunes con los mapas ortomosaicos
Los drones deberían facilitar la planificación de vuelos para la fotogrametría ortomosaica . Con pilotos expertos de drones al timón, la recopilación de imágenes debería implicar poco más que establecer una ruta de vuelo, lanzar el UAV y realizar el control de calidad de las imágenes una vez que se recopilan. Sin embargo, sin experiencia y una ejecución cuidadosa, surgen algunos problemas comunes:
Demasiados huecos . Las ortoimágenes deben superponerse lo suficiente como para que el software de procesamiento cree un mapa completo; de lo contrario , se producirán lagunas, inexactitudes y distorsión visual .
Detalle bajo . La mala iluminación, el mal tiempo y la tecnología desactualizada pueden llevar a cámaras desenfocadas que producen imágenes borrosas, viñetas y distorsiones que reducen la calidad de los datos.
Imágenes irrelevantes . Los conjuntos de datos que incluyen vistas no esenciales desde fuera de los parámetros de metadatos establecidos, por ejemplo, imágenes de despegue y aterrizaje fuera de ángulo o imágenes tomadas fuera del área objetivo, pueden introducir ambigüedad en su mapa.
Para producir mapas ortomosaicos de alta calidad, necesita un vuelo bien planificado y ejecutado profesionalmente.
¿Cómo se define la resolución en fotogrametría?
La calidad de una ortofoto se centra en tres formas de resolución: espacial, temporal y espectral.
¿Qué es la resolución espacial?
La resolución espacial describe la cantidad de datos visuales recopilados en cada píxel de la imagen. La resolución espacial se mide en términos físicos: un documento con una resolución de 100 m documenta 100 metros por 100 metros de datos claros por píxel.
¿Qué es la resolución temporal?
La resolución temporal es una métrica para describir cómo transcurrió el tiempo entre imágenes o conjuntos de datos, lo que afecta la calidad analítica. Una buena resolución temporal requiere la recopilación de datos a intervalos regulares con pocas lagunas sustanciales.
¿Qué es la resolución espectral?
La resolución espectral describe la capacidad de un sensor para recopilar información sobre longitudes de onda electromagnéticas. Un sensor puede ser adecuado para variaciones documentadas de color, luz infrarroja u otras formas de energía electromagnética.
La fotogrametría es más que un simple mapeo. La fotogrametría de drones está cambiando la forma en que documentamos, estudiamos y respondemos a las condiciones tanto en entornos naturales como artificiales.
¿Qué es la fotogrametría?
La fotogrametría es un proceso sofisticado mediante el cual se extrae información de fotografías para crear mapas y modelos tridimensionales precisos. Utilizando fotografías aéreas de ultra alta resolución, esta práctica combina sensores aéreos montados en vehículos aéreos no tripulados con potentes sistemas de mapeo GIS para crear documentos dinámicos y medibles para una serie de situaciones y usos del mundo real.
La fotogrametría tiene sus primeros orígenes en la vigilancia y el reconocimiento. Los pilotos durante la Primera Guerra Mundial combinaron nuevas innovaciones tanto en fotografía como en vuelo tripulado para recopilar información de detrás de las líneas enemigas. Las fotografías por sí solas no eran muy valiosas sin contexto, por lo que estos pioneros utilizaron puntos de referencia locales y características del paisaje para determinar la orientación de los objetos en las imágenes. En las décadas siguientes, estas prácticas evolucionarían con nuevas herramientas, desde aviones U2 estratosféricos hasta satélites meteorológicos avanzados y fotogrametría moderna con drones.
Los mapas fotogramétricos actuales se construyen utilizando un software GIS avanzado que puede generar mediciones de paisajes e infraestructura a nivel de topógrafo. Estos mapas son lo suficientemente detallados como para proporcionar información valiosa sobre las condiciones ambientales en el suelo al documentar la erosión, la densidad de la vegetación, la claridad del agua y más. Y ese es solo el comienzo de lo que puede hacer el software de fotogrametría.
Un glosario para principiantes de términos y conceptos de fotogrametría.
Antes de sumergirnos, aquí hay una introducción a algunos términos y conceptos clave que son fundamentales para tomar la mejor decisión de software de fotogrametría para su organización.
¿Qué es una ortofoto u ortoimagen?
Una ortofoto es una imagen aérea que se corrige geométricamente para producir una perspectiva y escala uniformes, por lo que se puede utilizar para medir diferencias reales.
Para producir una escala uniforme, la imagen debe corregirse en función de factores que incluyen la inclinación de la cámara, la distorsión de la lente y las condiciones ambientales.
¿Qué es un mapa ortomosaico?
Con un software avanzado, se puede unir una selección de ortofotos para producir un mapa 2D o 3D de las condiciones del terreno.
Un mapa ortomosaico es una pantalla interactiva sin distorsiones de imágenes de alta resolución que se puede utilizar para medir distancias precisas entre características geográficas reales.
¿Qué es la teledetección?
La teledetección describe un conjunto de tecnologías que utilizan sensores y fotografías aéreas para crear mapas detallados para la medición y el estudio.
La fotogrametría es una de las varias herramientas de la teledetección y se utiliza para procesar imágenes recopiladas por sensores montados en vehículos aéreos no tripulados, aviones tripulados y satélites. Otras formas de detección remota documentan la radiación infrarroja y ultravioleta, distancias punto por punto y más.
¿Qué es Structure from Motion (SfM)?
Structure from Motion es una técnica que calibra imágenes bidimensionales en una reconstrucción de una estructura, escena u objeto tridimensional.
Utilizando imágenes de superficie digital de ultra alta resolución, SfM puede producir increíbles modelos 3D basados en nubes de puntos con una calidad de medición similar a LiDAR.
¿Qué es un sistema de información geográfica (SIG)?
Los sistemas de información geográfica (SIG) se utilizan para anclar imágenes de alta resolución en datos de posicionamiento por satélite con fines cartográficos.
Google Earth es quizás el sistema SIG más ubicuo que existe, pero los datos del sistema de información geográfica también impulsan la meteorología, la topografía y el mapeo avanzados, la navegación y mucho más.
¿Qué son los metadatos?
Los metadatos son una serie de notas codificadas con datos recopiladas junto con ortoimágenes para proporcionar un contexto adicional para el software de creación de mapas y modelado. Los metadatos pueden incluir:
coordenadas GPS
Hora Fecha
Longitud focal
Configuraciones de resolución
Condiciones atmosféricas
Y más
Los metadatos les dirán a los usuarios las condiciones en las que se creó el conjunto de datos y quién lo creó, los cuales ofrecen información valiosa para construir una escala y perspectiva uniformes.
¿Cuál es la diferencia entre el mapeo 3D y el modelado 3D ?
Hay mucha superposición entre estas dos tecnologías. El mapeo 3D crea un mapa ortomosaico que tiene la textura y la dimensión visual de un modelo 3D, pero sigue siendo un documento fundamentalmente bidimensional.
El modelado 3D introduce profundidad en la ecuación de fotogrametría 3D al crear imágenes compuestas con altura también. Esta dimensión adicional permite al usuario ver estructuras y características ambientales desde múltiples ángulos.
Por ejemplo, los modelos de bienes raíces en 3D le permiten «caminar» o hacer un sobrevuelo en la propiedad para ver diferentes «lados» de una casa o paisaje haciendo clic en diferentes perspectivas en el mapa.
Este tutorial le presenta las características y procedimientos clave del software Datamine Studio RM que se utilizan en el proceso de modelado geológico al crear un modelo de cuerpo de mineral. En este tutorial, encontrará principios y ejercicios asociados con los siguientes temas:
Inicio de proyecto
Importación de contornos topográficos
Generación de perforaciones
Carga de datos de referencia 3D
Ayudas de modelado visual
Modelado de cadenas geológicas
Modelado geológico de estructura metálica
Modelado de bloques geológicos
Creando Isoshells
Base de datos para modelado geológico
El conjunto de datos de utilizado en este tutorial representa un depósito hidrotermal de Cu-Au poco profundo y consta de lo siguiente:
28 perforaciones (que contienen información sobre el tipo de roca, la densidad, el indicador de la zona de mineralización, la ley de oro y cobre)
Los descubrimientos científicos de los últimos años han enfatizado adecuadamente la fragilidad y la interconexión global de nuestro medio ambiente. Existe una creciente conciencia de las graves consecuencias globales de las perturbaciones ambientales, tanto por causas naturales como eventos de El Niño, erupciones volcánicas, huracanes, terremotos catastróficos y meteoritos impactos, y de causas humanas como la lluvia ácida, el calentamiento por efecto invernadero, el agotamiento del ozono atmosférico, la extinción de especies vivas y contaminación del suelo, el agua y el aire. Necesitamos con urgencia comprender mejor el medio ambiente global con el fin de desarrollar políticas nacionales e internacionales que prevengan o acomoden los cambios ambientales. El La comunidad científica en otros lugares está respondiendo a esta necesidad organizando y expandiendo los esfuerzos de investigación bajo el patrocinio del Programa Internacional de Geosfera-Biosfera del Consejo Internacional de Uniones Científicas, Programa de Investigación del Clima Mundial de la Organización Meteorológica Mundial y Programa de Investigación del Cambio Global de EE. UU.
Con el objeto de mejorar nuestro conocimiento de la superficie terrestre y cómo responde al cambio es de gran importancia en estos esfuerzos. A pesar de nuestra total dependencia de la tierra, estamos poniendo en peligro su riqueza por prácticas que causan daños como Pérdida irrecuperable de suelo, degradación de ecosistemas forestales y de tierras áridas y contaminación del suelo y el agua con contaminantes que están entrando y dañando la cadena alimentaria. Este informe centra la atención en los beneficios sociales y científicos oportunidades de un estudio exhaustivo por parte del Servicio Geológico de los Estados Unidos de los procesos geológicos que operan en la superficie de la tierra Describe las instrucciones para la investigación que proporcionarán la base para ayudar a rectificar una negligencia peligrosa de nuestros recursos de la tierra
Los tipos de modelos de bloques más comunes que se encuentran en la industria minera son Datamine, Vulcan, Surpac, Micromine y MineSight.
Los modelos de formato Datamine son actualmente el mejor formato para usar, ya que son compatibles con comandos extensos para interrogación y manipulación. Dado esto, hemos discutido este formato de archivo más extensamente que los otros formatos.
El formato Datamine estan disponibles públicamente y, por lo tanto, eran bien conocidos. Por lo tanto, muchos de los paquetes de modelado geológico admiten la exportación de sus modelos como modelos de Datamine. Otros formatos de modelos han tenido que determinarse mediante una interpretación juiciosa de prueba y error de lo que creemos que es la forma en que almacenan sus datos.
MB TIPO DATAMINE
Los modelos de bloques de Datamine se reconocerán por su sufijo: *.dm.
Hay dos limitaciones principales de los archivos Datamine que deben entenderse:
(a) Los archivos Datamine solo admiten ocho caracteres como nombres de campo.
(b) Los archivos de Datamine están limitados a un total de 256 campos (si están en el formato de precisión extendido predeterminado).
El formato Datamine tiene sus raíces en una larga historia. Datamine se fundó en 1981 y utiliza el sistema de gestión de base de datos relacional G-EXEC desarrollado por el Servicio Geológico Británico durante la década de 1970.
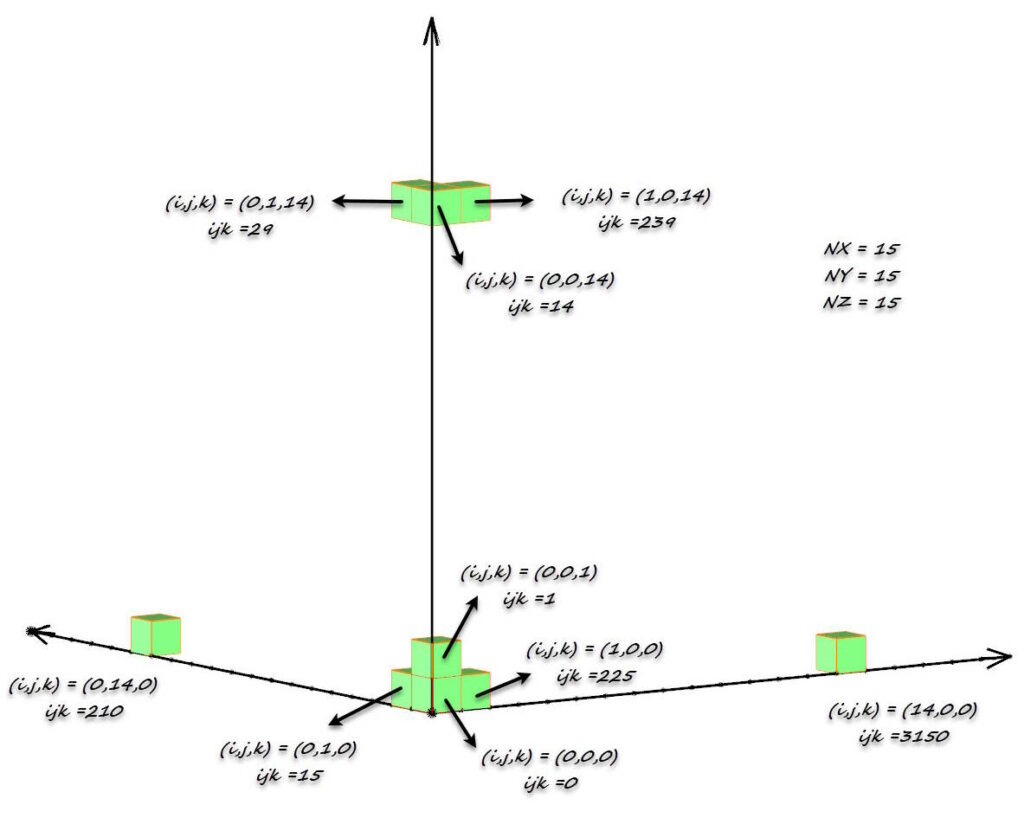
Los archivos Datamine son archivos de acceso aleatorio almacenados como tablas planas sin ninguna relación jerárquica o de red implícita. La estructura del modelo se define en un archivo de «prototipo de modelo» y el contexto espacial de cada bloque se almacena como parte del registro de cada bloque mediante posicionamiento implícito, lo que ahorra espacio de almacenamiento y tiempo de procesamiento. Esto se hace utilizando el código de indexación IJK (ver Figura 11 y Figura 12), lo que permite un acceso rápido por parte del programa de computadora a cualquier parte del modelo.
Datamine IJK schema
Algunas matemáticas relacionadas con el código IJK son:
IJK = NZ × NY × I + NZ × J + K
El IJK también se puede determinar a partir del sistema de coordenadas del modelo:
I = REDONDO[ (Xc-XParentINC/2)/XParentINC]*XParentINC – XmORIG)/XParentINC
K = REDONDO[ (Zc-ZParentINC/2)/ZParentINC]*ZParentINC –
ZmORIG)/ZParentINC
Donde XParentINC, YParentINC y ZParentINC son los X, Y y tamaños Z de los bloques principales (a cualquier subcelda).
La estructura del prototipo del modelo utiliza los campos que se muestran en la siguiente tabla.
Campos
Descripción
XMORIG, YMORIG, ZMORIG
Origen XYZ del modelo. Datamine establece el origen con respecto a la esquina de la primera celda principal y NO su centroide.
XINC, YINC, ZINC
Dimensiones de la celda XYZ (incrementos).
NX, NY, NZ
Número de celdas principales del modelo en XYZ. Datamine permite un valor de uno para el modelado de costuras. El número de celdas, en combinación con el tamaño principal de la celda, define la extensión de las dimensiones del modelo.
XC, YC, ZC
Coordenadas del centro de la celda XYZ.
IJK
Código generado y utilizado por Datamine para identificar de manera única cada posición de celda principal dentro del modelo. Las subceldas que se encuentran dentro de la misma celda principal tendrán el mismo valor IJK.
I
Posición del bloque (celda) a lo largo del eje x (cero «0» para la primera posición, y aumentando por valores enteros).
J
Posición del bloque (celda) a lo largo del eje y (cero «0» para la primera posición, y aumentando por valores enteros).
K
Posición del bloque (celda) a lo largo del eje z (cero «0» para la primera posición, y aumentando por valores enteros).
Datamine block model prototype structure fields
VERSIONES DEL FORMATO DATAMINE
Hay dos versiones del formato DM: precisión simple (SP) y precisión extendida (EP).
El formato DM de precisión simple original se basaba en «páginas» de 2048 bytes. (Estos son los registros de Fortran de palabras de 512 × 4 bytes). La primera página contenía la definición de datos mientras que las páginas siguientes contenían los registros de datos. Hay dos tipos de datos: texto o alfa («A») y números de punto flotante («N»).
Los elementos enteros en la página de definición de datos se almacenan como valores Fortran REAL4 o REAL8 en los formatos de precisión simple y extendida respectivamente.
Hay algunos códigos numéricos especiales que se utilizan dentro de los datos. -1.0 E30 = «abajo»; se utiliza como código de datos faltantes para campos numéricos, también conocido como «valor nulo». (Para los campos de texto, los datos que faltan son simplemente todos los espacios en blanco). +1.0 E30 = «superior»; y se usa si se necesita una representación de «infinito». +1.0 E-30 = «TR» o «DL»; se utiliza si se requiere para representar un valor de ensayo de «traza» o «por debajo del límite de detección».
Todos los datos de texto se mantienen en variables REALES, no en el tipo CARÁCTER de Fortran, aunque el formato almacenado es idéntico. Esto permite el uso de una matriz REAL simple para contener un búfer de página completo y otra matriz REAL para contener la totalidad de cada registro lógico para escritura o lectura. Este concepto se originó en el sistema G-EXEC del Servicio Geológico Británico en 1972 y fue la clave de la generalidad de Datamine, en lugar de tener que predefinir formatos de datos específicos para cada combinación diferente de texto y campos numéricos.
El formato de archivo Datamine de «precisión extendida» (EP) tiene páginas dos veces más grandes que el formato de archivo de «precisión simple» (4096 bytes de longitud) y la estructura de la página simplemente se asigna a palabras de 8 bytes en lugar de palabras de 4 bytes.
El formato de archivo Datamine de «precisión simple» es efectivamente un formato heredado y, con suerte, ahora no se encontrará con frecuencia. Estos archivos solo pueden tener 64 campos, mientras que los archivos de «doble precisión» pueden tener 256 campos.
El formato de archivo EP Datamine permite el Fortran REAL*8 completo (o DOUBLE PRECISION), pero para los datos de texto solo se utilizan los primeros cuatro bytes de cada palabra de doble precisión. Por lo tanto, la estructura de archivos EP es ineficiente en términos de almacenamiento de datos para archivos que tienen cantidades significativas de datos de texto.
Los modelos de bloques de Datamine tienen dos «niveles» de bloques: bloques principales y bloques secundarios (subbloques o subceldas). Cuando se crea un modelo de Datamine, el usuario especifica el tamaño del bloque principal, que será consistente durante la vida útil del modelo. Durante el proceso de creación de un modelo de bloques de Datamine, los subbloques se crean a lo largo de los límites para que un bloque principal pueda tener cualquier cantidad de bloques secundarios, y pueden ser de cualquier tamaño. Es posible que cada bloque principal tenga un número diferente de bloques secundarios.
DATAMINE – UNICODE
Los modelos de bloque Unicode de Datamine se reconocerán por su sufijo: *.dmu.
Una limitación importante con el formato de archivo Datamine es que almacena todo el texto en formato ASCII, que se desmorona cuando intenta trabajar en un lenguaje simbólico como ruso, polaco, japonés, chino, etc.
Tenga en cuenta que un modelo de bloque *.dmu tiene las siguientes características:
No hay límite en el tamaño del nombre del campo (solía tener ocho caracteres, ahora puede ser cualquier cosa).
Hay soporte para cualquier idioma, codificado directamente en el archivo.
Todavía hay un límite estricto de 256 campos, pero ahora su campo de texto solo cuenta para uno de esos campos. Anteriormente, si su columna de texto tenía un ancho de 20, contaría como cinco campos, por lo que ahora puede comprimir más campos de manera efectiva si está usando texto.
Hay disponibles longitudes de texto variables. Si tuviera una columna con AAAA y AAAAAAAA, necesitaría definir de antemano que la columna tiene ocho caracteres. Ahora, no le importa el número de caracteres (máximo o mínimo) que haya en una columna.
La recomendación es que probablemente no debería usar archivos *.dmu a menos que realmente tenga que hacerlo. Hay muchos más usuarios que usan archivos *.dm, por lo que es más probable encontrar y corregir cualquier error de software relacionado con los modelos de bloques para los archivos *.dm que para los archivos *.dmu.
Proxima entrega: Modelo de bloques en Surpac, Vulcan, Minesight y Micromine.
El modelado implícito es un enfoque de modelado espacial en el que la distribución de una variable objetivo se describe mediante una función matemática única que se deriva directamente de los datos subyacentes y los controles paramétricos de alto nivel especificados por el usuario. Este enfoque de modelado se puede aplicar a variables discretas como la litología (después de convertir los códigos discretos en valores numéricos) o a variables continuas como las leyes geoquímicas. Este artículo discute la estimación de variables continuas (leyes) utilizando el modelado implícito.
Uno de los motores subyacentes del modelado implícito para producir esta descripción de función matemática es la función de base radial (RBF). En esencia, la RBF es una suma ponderada de funciones posicionadas en cada punto de datos. Se resuelve un sistema de ecuaciones lineales para derivar los pesos y los coeficientes de cualquier modelo de deriva subyacente. Una vez derivada, la RBF se puede resolver para cualquier punto no muestreado o promediarse sobre cualquier volumen para proporcionar una estimación de grado. Es posible, por ejemplo, consultar la RBF en una rejilla regular para obtener una estimación de los grados de bloque. Dada la facilidad de creación de una RBF y su capacidad para predecir el grado, surge la pregunta de cómo se comparan los grados derivados de la solución de una RBF con las estimaciones de grado derivadas de métodos convencionales de interpolación geoestadística (por ejemplo, kriging ordinario (OK)).
El propósito de este artículo es describir en términos sencillos:
• la estructura básica de una RBF
• el papel de la elección paramétrica en la solución de las RBF y cómo esto influye en el carácter de la solución
• las similitudes y diferencias fundamentales entre las RBF y los estimadores geoestadísticos convencionales.
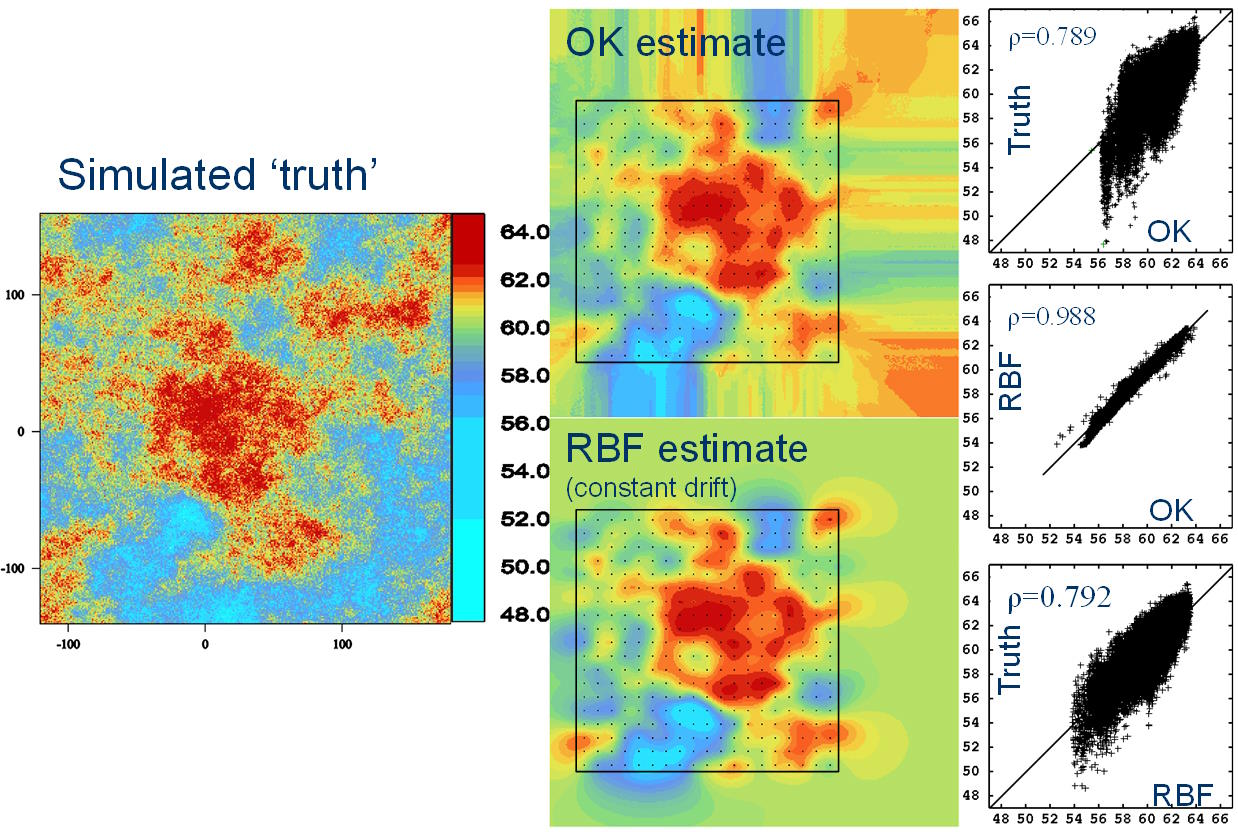
Utilizando una simulación condicional de alta resolución, se muestra que en muchas situaciones, las estimaciones de la RBF y el OK son muy similares.
INTRODUCCIÓN
En los últimos años, los modelos alámbricos implícitos se han utilizado cada vez más para desarrollar formas 3D coherentes para su uso posterior en la estimación a través de métodos tradicionales (por ejemplo, kriging ordinario (OK)). Cowan et al (2003) introdujeron el término «modelado implícito» en la tarea de modelar geometrías de superficies geológicas. El modelado implícito describe un enfoque del modelado espacial en el que una combinación de datos y controles paramétricos especificados por el usuario definen una función de volumen matemática única. Este enfoque puede aplicarse al modelado de superficies a partir de variables categóricas, como la litología, o al modelado de variables continuas, como leyes geoquímicas en todo el espacio. La función más común actualmente en uso para el modelado implícito es la función de base radial (RBF). El término implícito se usa porque la superficie que se modela existe implícitamente dentro de la función de volumen como una superficie isopotencial definida por los datos en lugar de por un proceso de dibujo explícito. Esta función de volumen puede luego ser cuadriculada, o ‘renderizada’, en una estructura alámbrica para su visualización o posterior uso de modelado.
El método de modelado implícito ahora se usa ampliamente para el modelado de la geometría de la superficie a partir de datos de registro categóricos y para el modelado de «isosuperficies de grado» basadas en variables de grado continuo. Lo que muchas personas desconocen es que los modelos implícitos utilizados para generar «isosuperficies de ley» también pueden proporcionar estimaciones puntuales o de bloque de la ley. En muchas situaciones, son muy similares a las estimaciones obtenidas con métodos de estimación más familiares, como OK. Hay una razón para esto: se puede demostrar (Carr et al, 2001; Chiles y Delfiner, 1999; Costa, Pronzato y Thierry, 1999) que el RBF es matemáticamente equivalente a una formulación particular de kriging (kriging dual (DK) ). En la práctica, las estimaciones derivadas de los RBF también suelen ser muy similares a las producidas por OK.
El propósito de este documento es describir (en términos simples) la estructura básica de un RBF e ilustrar las similitudes que tiene con el kriging. También discutiremos brevemente el papel de la elección de parámetros en la solución de RBF y mostraremos cómo esto influye en el carácter de la solución.
LA IDEA DE LA INTERPOLACIÓN
La interpolación es el proceso de predecir (estimar) el valor de un atributo en una ubicación no muestreada a partir de mediciones del atributo realizadas en los sitios circundantes (Figura 1). En la interpolación lineal, la calificación en la ubicación objetivo se calcula como un promedio lineal ponderado de los datos de la muestra. Diferentes interpoladores usan diferentes métodos para determinar el valor de los pesos. Cuando el punto a estimar está dentro del campo de datos disponibles, el proceso se denomina interpolación; cuando el punto está fuera del campo de datos, el proceso se denomina extrapolación. Este proceso puede realizarse en una, dos, tres o cuatro dimensiones. Por lo general, en la estimación de recursos minerales, nos preocupamos por problemas prácticos tridimensionales: predecir la ley de un atributo (por ejemplo, una ley de metal) en ubicaciones no muestreadas a partir de valores medidos en muestras de perforación dispersas. Es una suposición subyacente que el atributo que intentamos predecir es espacialmente continuo, que toma un valor real en todas las ubicaciones posibles. Hay muchas formas diferentes de interpolador posibles. El más básico es el método constante por partes, más conocido como estimación del vecino más cercano, en el que cualquier ubicación no muestreada simplemente toma el valor del punto de datos más cercano. El estimador continuo resultante toma la forma de un patrón de mosaico, con parches de ley constante separados por pasos repentinos. Esta no es una representación muy realista de la forma en que se observa que los atributos reales, como las leyes del metal, varían en la práctica, y otorga pesos significativamente diferentes a las muestras en los extremos espaciales del conjunto de datos. En aras de la simplicidad en la discusión, este documento considerará que el atributo que se predice es el grado de un metal, sin embargo, la idea puede extenderse simplemente a cualquier variable continua.
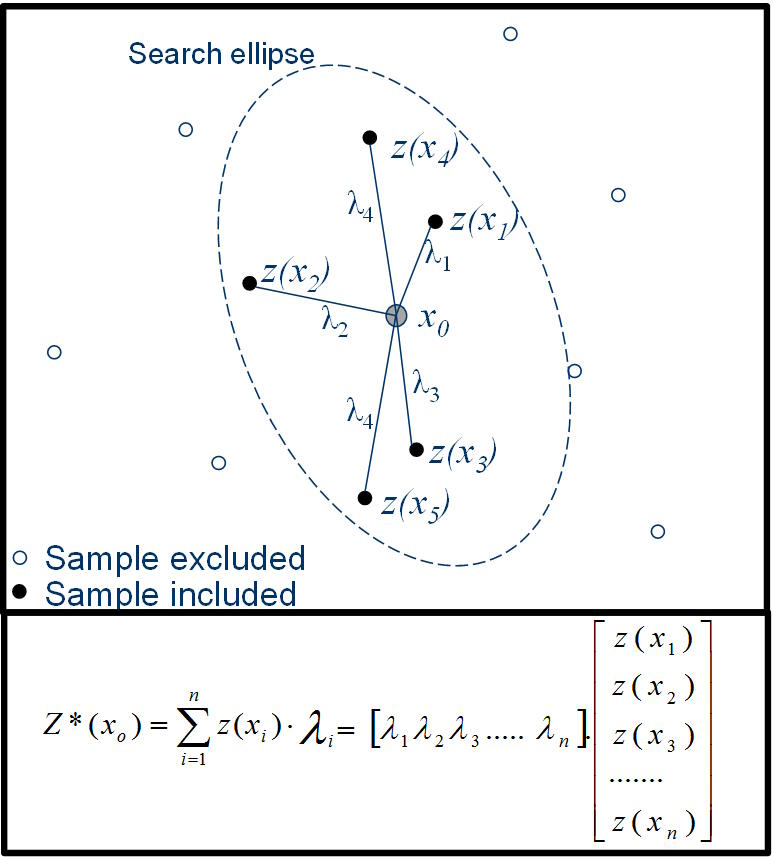
El interpolador kriging (local)
Los interpoladores se dividen en dos tipos generales: globales o locales. Un interpolador global tiene en cuenta todos los puntos conocidos para estimar un valor, mientras que la interpolación local utiliza un subconjunto de datos, generalmente definido por una vecindad de búsqueda centrada en el punto que se estima.
El interpolador que probablemente se usa más comúnmente en minería es kriging, o más particularmente OK. La idea general es sencilla: la estimación de un punto se basa en una combinación lineal ponderada de valores de datos locales, y los pesos se calculan de tal manera que se minimiza la varianza del error en función de un modelo asumido para la covarianza espacial. Kriging se basa en una serie de suposiciones clave:
La suposición subyacente es que las observaciones de la muestra se interpretan como los resultados de un proceso aleatorio. La variable en estudio (por ejemplo, grado de Fe
s) se puede describir mediante una función aleatoria matemática. Esta conceptualización de los datos es simplemente un ingenioso truco que nos permite describir la realidad como el resultado de un modelo probabilístico.
El paso clave en el modelado geoestadístico es la adopción de un modelo espacial (el variograma) que describe la función aleatoria subyacente. La elección del modelo espacial normalmente se basa en ajustar una función a los datos experimentales disponibles, aunque no existe un vínculo explícito y esta función a menudo se elige más por conveniencia matemática que por derivarse de un análisis del proceso de mineralización.
La adopción de un modelo que resume el proceso aleatorio permite que la varianza del error (la varianza de la diferencia «en promedio» entre la calificación estimada y la verdadera) se exprese en términos de covarianzas espaciales y factores de ponderación aplicados a las muestras (pesos kriging). Las covarianzas espaciales se especifican mediante la elección del modelo de variograma realizado y las ubicaciones de los datos. El álgebra convencional proporciona los medios para encontrar el conjunto de pesos de kriging que minimiza la varianza del error.
Estos atributos son característicos de todos los sistemas kriging. Las variantes más comunes de kriging son kriging simple (SK), OK y kriging universal (UK). Lo que los distingue es la forma en que la variación en la ley media (deriva) se incorpora a los sistemas kriging.
Diferentes sistemas de kriging
Como se explicó anteriormente, lo que distingue a los diferentes sistemas de kriging es la forma en que se incorpora la variación en la ley media (deriva) en los sistemas de kriging.
kriging simple
SK asume que la expectativa de la media (m) es constante en todo el dominio y de valor conocido (estacionariedad intrínseca). Esto equivale a decir que la componente de deriva es constante y conocida. Por lo general, se estima utilizando la media desagregada de los datos muestrales disponibles.
El estimador SK en cualquier punto se reduce a una combinación de dos componentes: un promedio ponderado de los datos locales y la media del dominio. Las estimaciones cercanas a los datos darán más peso a la estimación local, mientras que las estimaciones más alejadas de los datos estarán dominadas por la media del dominio.
SK rara vez se usa en la práctica ya que la suposición subyacente (constante, media conocida) es demasiado severa para la mayoría de las aplicaciones. Además, la incorporación de la nota media como término ponderado en la estimación SK hace que, lejos de la influencia
de datos de la muestra, el estimador vuelve a la nota media. En la mayoría de los depósitos minerales, la ley disminuye hacia el margen y, a menudo, aquí es donde los datos de perforación son más bajos. Tener un estimador que revierte hacia la media en esta región generalmente no es realista.
kriging ordinario
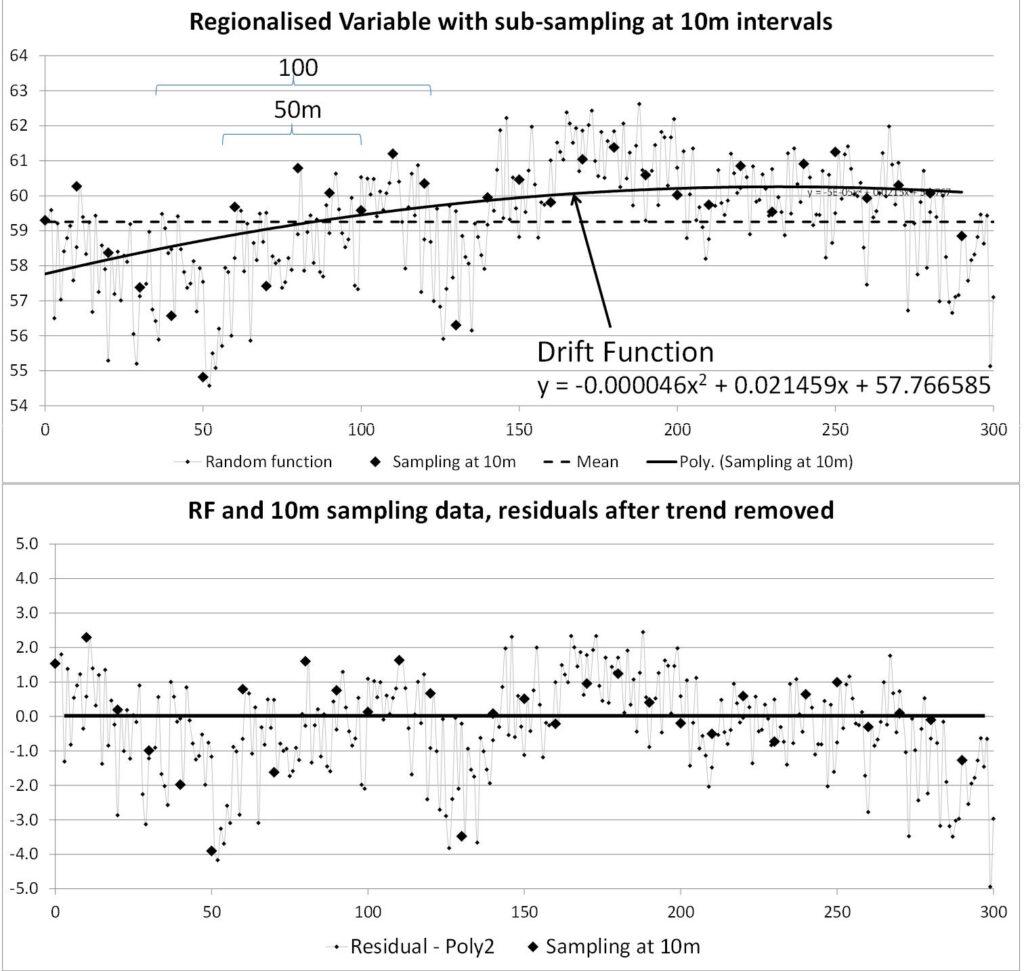
La suposición que distingue a OK de otros sistemas de kriging es que la expectativa de la media es desconocida pero es constante a la escala de la vecindad de búsqueda (una suposición conocida como cuasiestacionariedad dentro de la hipótesis intrínseca). Lo que esto significa en la práctica es que no debería haber tendencias presentes en la calificación media local por debajo de la escala de la búsqueda. Este es un concepto algo resbaladizo ya que es inusual tener una escala clara en la que se aplica esta separación. En la práctica, esto significa que las variaciones en las calificaciones muestreadas presentes dentro de un vecindario local deben ser fluctuaciones aleatorias plausibles en torno a una calificación media local constante, sin que se presente una fuerte tendencia. Esto permite que el sistema OK se adapte a la variación en la media local de modo que la estimación siempre se centre en el promedio ponderado de las muestras presentes en el vecindario local. Esto significa que la especificación de la vecindad de búsqueda local tiene una influencia crítica en la calidad del estimador kriging; en particular, la vecindad debe ser lo suficientemente grande para que los datos contenidos representen adecuadamente la ley media local.
Al extrapolar más allá de los límites de los datos, el estimador OK no revierte hacia la media global, sino que mantiene la media local especificada por las muestras más cercanas.
kriging universal
La teoría de UK fue propuesta por Matheron en 1969 (Armstrong, 1984) para proporcionar una solución general a la estimación lineal en presencia de deriva. Esta teoría asume que la media local es desconocida pero varía de manera sistemática y puede escribirse como una expansión finita de funciones de base conocidas (f) y coeficientes fijos (pero desconocidos) (a). La información de deriva puede entonces incorporarse en la expresión de la varianza de la estimación.
Rápidamente se dio cuenta de que existen graves dificultades prácticas en la implementación del Reino Unido. El desarrollo del sistema del Reino Unido supone que se conoce el variograma subyacente (que incorpora la deriva); en esta situación, el sistema kriging arroja correctamente tanto los coeficientes de deriva como los pesos. En la práctica, sin embargo, el variograma subyacente siempre se desconoce. Esto nos deja con un problema circular; para calcular los residuos necesitamos conocer la deriva,
pero para conocer la deriva necesitamos conocer el sistema del Reino Unido. Esta circularidad no excluye el uso de UK, pero sí significa que se debe tener mucha cautela en su aplicación. Asumir un modelo de deriva y trabajar solo con residuos dará como resultado una estimación sesgada del verdadero variograma subyacente (Armstrong, 1984).
Doble kriging
Los estimadores de kriging discutidos anteriormente se basan en combinaciones lineales de valores de datos de muestra. También es posible reescribir el estimador UK en términos de covarianzas σ(xi,x) y funciones de deriva f l(x) únicamente, omitiendo cualquier referencia directa a los datos. Esto se conoce como DK. El desarrollo no se muestra aquí, pero se da una exposición clara en Chiles y Delfiner (1999) y Galli, Murillo y Thomann (1984). El término ‘dual’ se origina de una derivación alternativa de estas ecuaciones por minimización en un espacio funcional, similar a splines (Chiles y Delfiner, 1999).
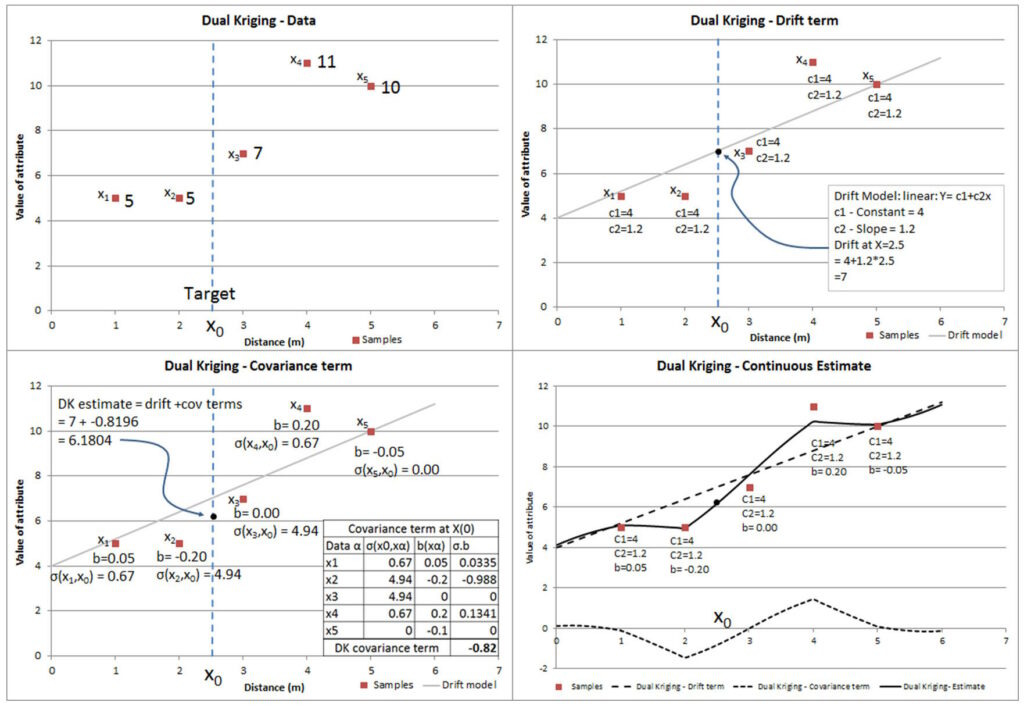
Expresado en inglés, la estimación en cualquier punto (x0) es la suma de dos componentes:
Un componente determinista transportado por la suma de los términos de la función de deriva en la ubicación objetivo: c f (x)
Un componente probabilístico calculado como la suma ponderada de las covarianzas entre la ubicación objetivo y todas las ubicaciones de muestra: b v(x ,x)
la función de covarianza (o variograma) es mayor en distancias cortas, es fácil ver que este término será mayor cuando el punto objetivo esté cerca de los datos. Los valores del coeficiente b están influenciados por el agrupamiento y la distancia del valor de la muestra de la ley media local estimada por el modelo de deriva.
La naturaleza de la función de deriva es una elección impuesta por el usuario, y la función de covarianza (o variograma en el caso intrínseco) es igualmente una elección especificada por el usuario. Luego, los valores de los coeficientes b y c se calculan de la misma manera que para otros sistemas de kriging, imponiendo restricciones en el sistema que permiten obtener una solución única (ver Chiles y Delfiner (1999) para más detalles).
Este sistema no es fácil de visualizar. La Figura 3 muestra cómo el estimador DK se compone de deriva y componentes probabilísticos, y que ninguno hace referencia directa a los valores muestreados. Tenga en cuenta que, si bien la estimación de deriva (y los coeficientes) y la estimación probabilística (y los coeficientes) se muestran por separado, en realidad se derivan simultáneamente. La deriva afecta la estimación en todo el espacio, mientras que los coeficientes probabilísticos describen la influencia local alrededor de cada punto de datos.
Una de las principales ventajas del sistema DK es que los coeficientes de deriva y covarianza solo necesitan resolverse una vez y luego pueden usarse para hacer una estimación en cualquier ubicación.
El principal inconveniente del método es que el uso de una vecindad global da como resultado un sistema muy grande de ecuaciones simultáneas, con una ecuación por muestra y una para cada función de deriva.
Funciones de base radial
El RBF es una familia de técnicas matemáticas que se ha aplicado a muchos problemas de interpolación espacial y es la base de la mayoría de los algoritmos de «modelado implícito» que se utilizan en la actualidad. Se basa en una premisa de partida algo diferente a la teoría de las variables regionalizadas en la que se basa el kriging: en lugar de considerar que la variable objetivo es una realización de una función aleatoria con una estructura definida, el RBF se basa en la interpolación de una función predefinida de criterios matemáticos como la minimización de la curvatura. En la práctica, esta diferencia es solo semántica, porque el kriging tradicional también usa determinadas funciones, excepto que estas se ajustan a los datos experimentales y se han elegido para adaptarse al modelado de los datos. Matemáticamente, existe una equivalencia entre DK y el modelado con RBF, y también es posible elegir la función RBF ajustando los datos experimentales. De hecho, debido a que los variogramas como el esférico son definidos positivos (Chiles y Delfiner, 1999, p. 59), son adecuados para usarse como RBF.
El interpolante para un RBF tiene una forma muy similar a la expresión general de kriging: la variable objetivo es se considera que está compuesto por un término de deriva y un término que es un promedio ponderado de los valores de función que dependen de las ubicaciones de los datos.
El término de la derecha se refiere al conjunto de K funciones de deriva (qk(x)), cada una de las cuales tiene un coeficiente (ck) aplicado globalmente a todos los datos.
De la misma manera que para DK, se imponen condiciones que hacen que el sistema sea solucionable. En este caso, las condiciones son que: el producto de los coeficientes RBF y los coeficientes de la función de deriva en cada punto de datos debe sumar cero en todos los puntos de datos, y la función debe devolver el valor de los datos en un punto de datos (ver Cowan et al. (2001) para detalles y Chiles y Delfiner (1999) para el ejemplo paralelo de DK). Estas condiciones permiten expresar el sistema como un conjunto de ecuaciones lineales. Esto se muestra en forma de matriz de la siguiente manera:
Accede al articulo completo en nuestra biblioteca Digital.
📚✨ Ahora todos nuestros cursos exclusivos están disponibles en YouTube Miembros y Patreon.
Únete hoy y accede a contenido avanzado, guías especializadas y soporte directo. 🎥🔥