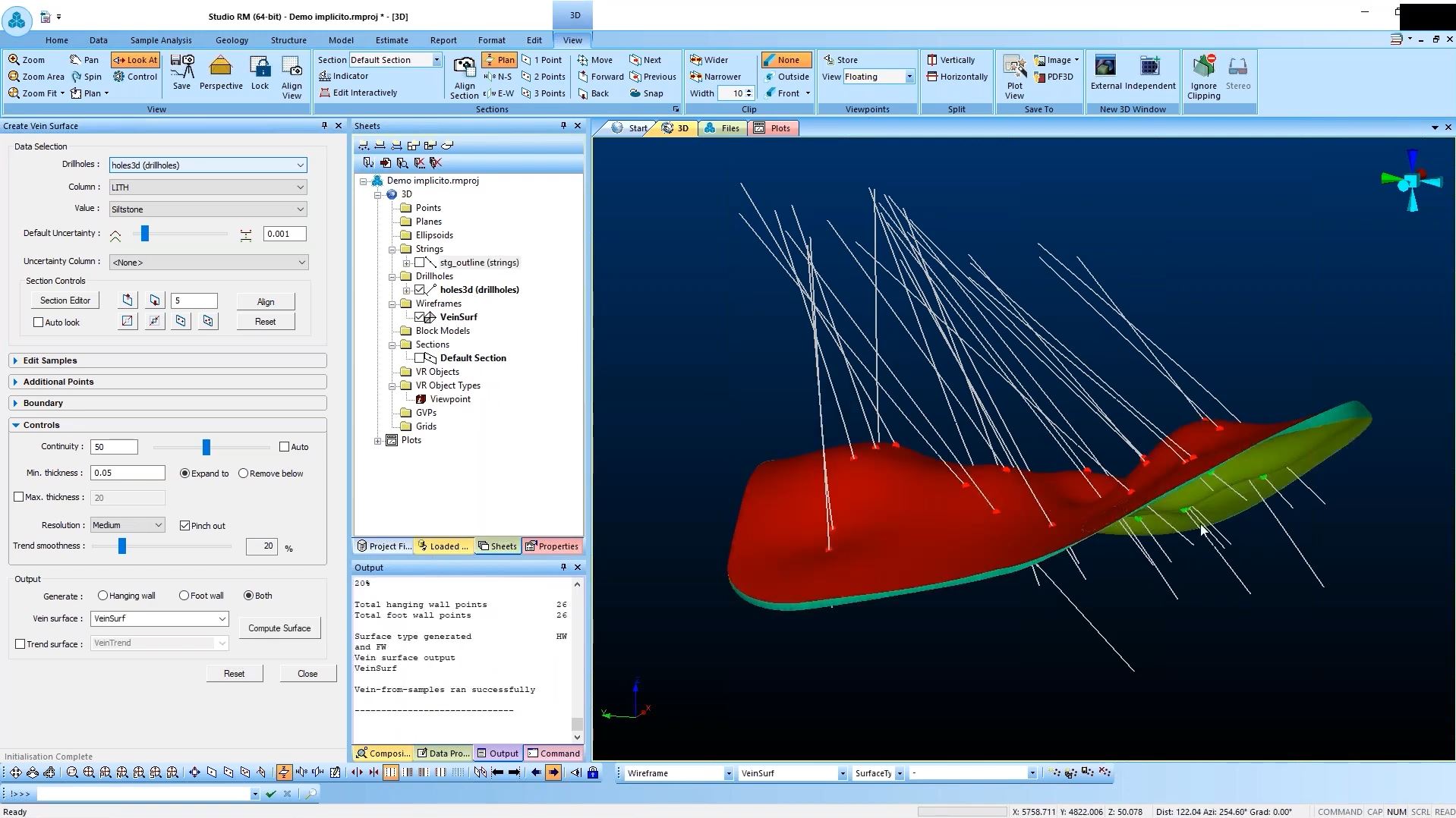
Datamine Studio RM contiene nuevos comandos para el modelado de intrusiones, cuerpos geológicos de forma compleja o irregular, envolventes de grado a un valor de corte y vetas masivas, cortantes o de stockworks. Ya sea que esté modelando estructuras geológicas o conchas de grado, tiene acceso a nuevas herramientas de elipsoides para controlar los cambios en la tendencia y resolución de su modelo estructural.
Una gran característica es que los elipsoides se pueden calcular automáticamente a partir de datos de muestra seleccionados. Al seleccionar muestras en áreas con una tendencia distintiva, el geólogo puede ejercer un control preciso sobre cómo se generan las superficies estructurales.
En esta oportunidad compartimos el tutorial para el modelado de vetas impartido por Datamine «Modelamiento Implícito de Vetas con Studio RM»
Introducción: La estimación de recursos es un proceso delicado y complejo, similar a un “castillo de naipes”. Cada etapa del proceso, desde el muestreo y la observación geológica hasta la geoestática y el modelado de recursos, es crucial para el resultado final. Este artículo explora la importancia del Aseguramiento y Control de Calidad (QA-QC) en este proceso.
Objetivos del Aseguramiento y Control de Calidad (QA-QC): Un buen programa de QA-QC tiene tres objetivos principales. Primero, prevenir la entrada de grandes errores en la base de datos utilizada para el modelado de recursos. Esto se logra a través de una serie de controles y balances que garantizan la precisión y consistencia de los datos recopilados.
Segundo, demostrar que las discrepancias en los muestreos y análisis son pequeñas en comparación con las variaciones geológicas. Esto se logra a través de la comparación constante de los datos recopilados con los estándares conocidos y la repetición regular de las pruebas para verificar su consistencia.
Tercero, garantizar que la precisión de la información utilizada para el modelo de recursos pueda ser confirmada por otros laboratorios, ensayos metalúrgicos y, finalmente, por la producción del molino y de la mina. Esto se logra a través del uso de técnicas estadísticas rigurosas y el seguimiento constante del rendimiento del laboratorio.
El papel del QA-QC en la factibilidad: El documento de factibilidad debe incluir evidencia que respalde la validez de la información utilizada para construir el modelo de recursos. Esto incluye ensayos, geología y geotecnia. Este documento se centra en la calidad de los ensayos e incluye algunas consideraciones geológicas y geotécnicas.
Conclusión: Además de ser un requisito para producir un documento de factibilidad integral, el Aseguramiento y Control de Calidad (QA-QC) es vital para garantizar la precisión y fiabilidad de los modelos de recursos. Al implementar un programa sólido de QA-QC, las empresas mineras pueden asegurarse de que sus estimaciones de recursos sean lo más precisas posible, lo que a su vez puede llevar a una mayor eficiencia operativa y rentabilidad.
La estimación de recursos es un proceso crucial en la gestión de proyectos. Consiste en planificar y garantizar la disponibilidad de los recursos necesarios para asegurar el buen desarrollo y éxito de un proyecto1. Este proceso debe tenerse en cuenta incluso antes de que el proyecto comience1.
Un buen programa de estimación de recursos tiene tres objetivos principales:
Prevenir la entrada de grandes errores en la base de datos utilizada para el modelado de recursos.
Demostrar que las discrepancias en los muestreos y análisis son pequeñas en comparación con las variaciones geológicas.
Garantizar que la precisión de la información utilizada para el modelo de recursos pueda ser confirmada por otros laboratorios, ensayos metalúrgicos y, finalmente, por la producción del molino y de la mina.
Los recursos pueden ser de varios tipos, incluyendo recursos humanos, materiales, financieros y temporales. La gestión de las cantidades de recursos necesarios, así como su optimización, son dos de los factores clave para cumplir a cabalidad con la entrega de un proyecto.
La estimación de los recursos está anclada a la gestión de un proyecto en el sentido más amplio, pues incluye diferentes aspectos relacionados con el proceso, tales como: la proyección de la duración y coste de las actividades (presupuesto provisional), la estructura de desglose de los recursos identificados por categorías (humanos, materiales, etc.), la asignación de recursos para cada actividad (según los perfiles y habilidades)
Los tipos de modelos de bloques más comunes que se encuentran en la industria minera son Datamine, Vulcan, Surpac, Micromine y MineSight.
Los modelos de formato Datamine son actualmente el mejor formato para usar, ya que son compatibles con comandos extensos para interrogación y manipulación. Dado esto, hemos discutido este formato de archivo más extensamente que los otros formatos.
El formato Datamine estan disponibles públicamente y, por lo tanto, eran bien conocidos. Por lo tanto, muchos de los paquetes de modelado geológico admiten la exportación de sus modelos como modelos de Datamine. Otros formatos de modelos han tenido que determinarse mediante una interpretación juiciosa de prueba y error de lo que creemos que es la forma en que almacenan sus datos.
MB TIPO DATAMINE
Los modelos de bloques de Datamine se reconocerán por su sufijo: *.dm.
Hay dos limitaciones principales de los archivos Datamine que deben entenderse:
(a) Los archivos Datamine solo admiten ocho caracteres como nombres de campo.
(b) Los archivos de Datamine están limitados a un total de 256 campos (si están en el formato de precisión extendido predeterminado).
El formato Datamine tiene sus raíces en una larga historia. Datamine se fundó en 1981 y utiliza el sistema de gestión de base de datos relacional G-EXEC desarrollado por el Servicio Geológico Británico durante la década de 1970.
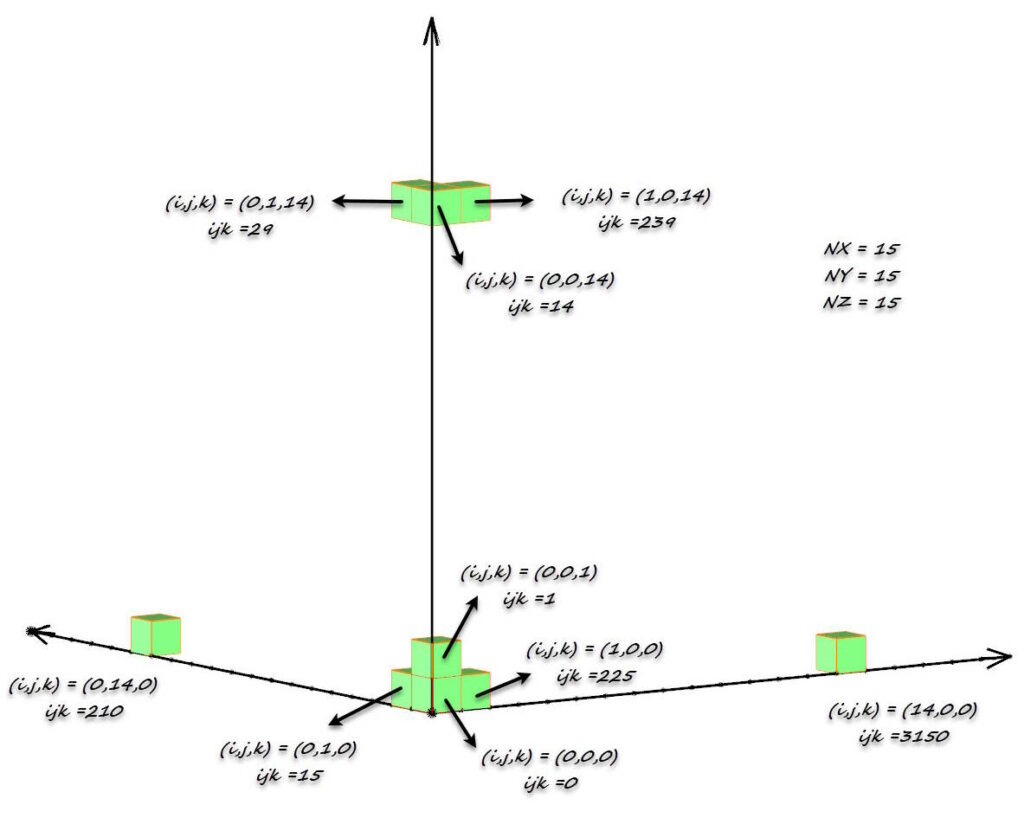
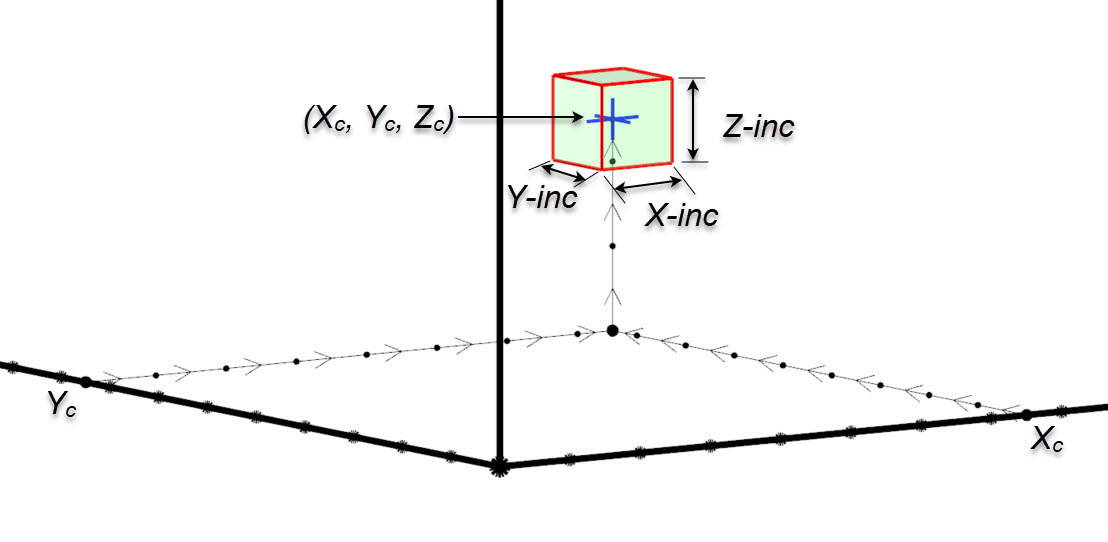
Los archivos Datamine son archivos de acceso aleatorio almacenados como tablas planas sin ninguna relación jerárquica o de red implícita. La estructura del modelo se define en un archivo de «prototipo de modelo» y el contexto espacial de cada bloque se almacena como parte del registro de cada bloque mediante posicionamiento implícito, lo que ahorra espacio de almacenamiento y tiempo de procesamiento. Esto se hace utilizando el código de indexación IJK (ver Figura 11 y Figura 12), lo que permite un acceso rápido por parte del programa de computadora a cualquier parte del modelo.
Datamine IJK schema
Algunas matemáticas relacionadas con el código IJK son:
IJK = NZ × NY × I + NZ × J + K
El IJK también se puede determinar a partir del sistema de coordenadas del modelo:
I = REDONDO[ (Xc-XParentINC/2)/XParentINC]*XParentINC – XmORIG)/XParentINC
K = REDONDO[ (Zc-ZParentINC/2)/ZParentINC]*ZParentINC –
ZmORIG)/ZParentINC
Donde XParentINC, YParentINC y ZParentINC son los X, Y y tamaños Z de los bloques principales (a cualquier subcelda).
La estructura del prototipo del modelo utiliza los campos que se muestran en la siguiente tabla.
Campos
Descripción
XMORIG, YMORIG, ZMORIG
Origen XYZ del modelo. Datamine establece el origen con respecto a la esquina de la primera celda principal y NO su centroide.
XINC, YINC, ZINC
Dimensiones de la celda XYZ (incrementos).
NX, NY, NZ
Número de celdas principales del modelo en XYZ. Datamine permite un valor de uno para el modelado de costuras. El número de celdas, en combinación con el tamaño principal de la celda, define la extensión de las dimensiones del modelo.
XC, YC, ZC
Coordenadas del centro de la celda XYZ.
IJK
Código generado y utilizado por Datamine para identificar de manera única cada posición de celda principal dentro del modelo. Las subceldas que se encuentran dentro de la misma celda principal tendrán el mismo valor IJK.
I
Posición del bloque (celda) a lo largo del eje x (cero «0» para la primera posición, y aumentando por valores enteros).
J
Posición del bloque (celda) a lo largo del eje y (cero «0» para la primera posición, y aumentando por valores enteros).
K
Posición del bloque (celda) a lo largo del eje z (cero «0» para la primera posición, y aumentando por valores enteros).
Datamine block model prototype structure fields
VERSIONES DEL FORMATO DATAMINE
Hay dos versiones del formato DM: precisión simple (SP) y precisión extendida (EP).
El formato DM de precisión simple original se basaba en «páginas» de 2048 bytes. (Estos son los registros de Fortran de palabras de 512 × 4 bytes). La primera página contenía la definición de datos mientras que las páginas siguientes contenían los registros de datos. Hay dos tipos de datos: texto o alfa («A») y números de punto flotante («N»).
Los elementos enteros en la página de definición de datos se almacenan como valores Fortran REAL4 o REAL8 en los formatos de precisión simple y extendida respectivamente.
Hay algunos códigos numéricos especiales que se utilizan dentro de los datos. -1.0 E30 = «abajo»; se utiliza como código de datos faltantes para campos numéricos, también conocido como «valor nulo». (Para los campos de texto, los datos que faltan son simplemente todos los espacios en blanco). +1.0 E30 = «superior»; y se usa si se necesita una representación de «infinito». +1.0 E-30 = «TR» o «DL»; se utiliza si se requiere para representar un valor de ensayo de «traza» o «por debajo del límite de detección».
Todos los datos de texto se mantienen en variables REALES, no en el tipo CARÁCTER de Fortran, aunque el formato almacenado es idéntico. Esto permite el uso de una matriz REAL simple para contener un búfer de página completo y otra matriz REAL para contener la totalidad de cada registro lógico para escritura o lectura. Este concepto se originó en el sistema G-EXEC del Servicio Geológico Británico en 1972 y fue la clave de la generalidad de Datamine, en lugar de tener que predefinir formatos de datos específicos para cada combinación diferente de texto y campos numéricos.
El formato de archivo Datamine de «precisión extendida» (EP) tiene páginas dos veces más grandes que el formato de archivo de «precisión simple» (4096 bytes de longitud) y la estructura de la página simplemente se asigna a palabras de 8 bytes en lugar de palabras de 4 bytes.
El formato de archivo Datamine de «precisión simple» es efectivamente un formato heredado y, con suerte, ahora no se encontrará con frecuencia. Estos archivos solo pueden tener 64 campos, mientras que los archivos de «doble precisión» pueden tener 256 campos.
El formato de archivo EP Datamine permite el Fortran REAL*8 completo (o DOUBLE PRECISION), pero para los datos de texto solo se utilizan los primeros cuatro bytes de cada palabra de doble precisión. Por lo tanto, la estructura de archivos EP es ineficiente en términos de almacenamiento de datos para archivos que tienen cantidades significativas de datos de texto.
Los modelos de bloques de Datamine tienen dos «niveles» de bloques: bloques principales y bloques secundarios (subbloques o subceldas). Cuando se crea un modelo de Datamine, el usuario especifica el tamaño del bloque principal, que será consistente durante la vida útil del modelo. Durante el proceso de creación de un modelo de bloques de Datamine, los subbloques se crean a lo largo de los límites para que un bloque principal pueda tener cualquier cantidad de bloques secundarios, y pueden ser de cualquier tamaño. Es posible que cada bloque principal tenga un número diferente de bloques secundarios.
DATAMINE – UNICODE
Los modelos de bloque Unicode de Datamine se reconocerán por su sufijo: *.dmu.
Una limitación importante con el formato de archivo Datamine es que almacena todo el texto en formato ASCII, que se desmorona cuando intenta trabajar en un lenguaje simbólico como ruso, polaco, japonés, chino, etc.
Tenga en cuenta que un modelo de bloque *.dmu tiene las siguientes características:
No hay límite en el tamaño del nombre del campo (solía tener ocho caracteres, ahora puede ser cualquier cosa).
Hay soporte para cualquier idioma, codificado directamente en el archivo.
Todavía hay un límite estricto de 256 campos, pero ahora su campo de texto solo cuenta para uno de esos campos. Anteriormente, si su columna de texto tenía un ancho de 20, contaría como cinco campos, por lo que ahora puede comprimir más campos de manera efectiva si está usando texto.
Hay disponibles longitudes de texto variables. Si tuviera una columna con AAAA y AAAAAAAA, necesitaría definir de antemano que la columna tiene ocho caracteres. Ahora, no le importa el número de caracteres (máximo o mínimo) que haya en una columna.
La recomendación es que probablemente no debería usar archivos *.dmu a menos que realmente tenga que hacerlo. Hay muchos más usuarios que usan archivos *.dm, por lo que es más probable encontrar y corregir cualquier error de software relacionado con los modelos de bloques para los archivos *.dm que para los archivos *.dmu.
Proxima entrega: Modelo de bloques en Surpac, Vulcan, Minesight y Micromine.
El modelado implícito es un enfoque de modelado espacial en el que la distribución de una variable objetivo se describe mediante una función matemática única que se deriva directamente de los datos subyacentes y los controles paramétricos de alto nivel especificados por el usuario. Este enfoque de modelado se puede aplicar a variables discretas como la litología (después de convertir los códigos discretos en valores numéricos) o a variables continuas como las leyes geoquímicas. Este artículo discute la estimación de variables continuas (leyes) utilizando el modelado implícito.
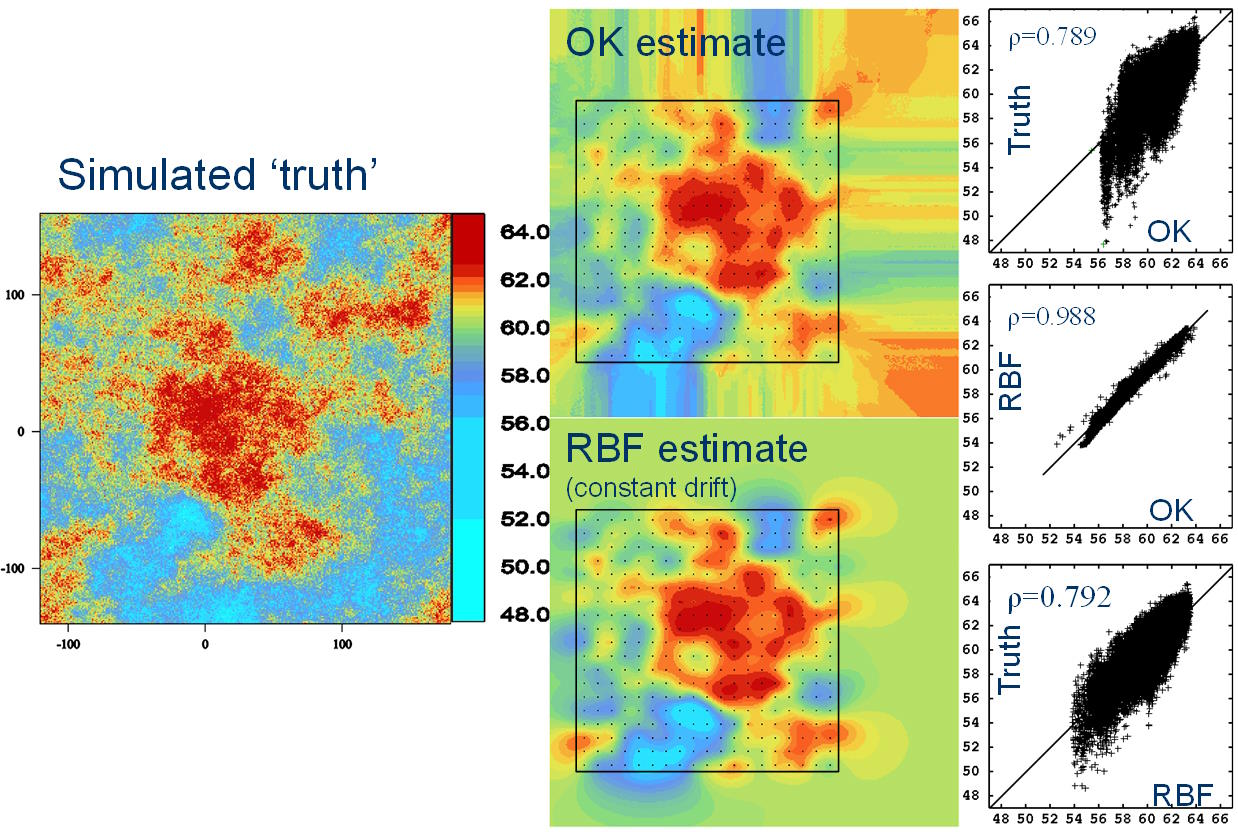
Uno de los motores subyacentes del modelado implícito para producir esta descripción de función matemática es la función de base radial (RBF). En esencia, la RBF es una suma ponderada de funciones posicionadas en cada punto de datos. Se resuelve un sistema de ecuaciones lineales para derivar los pesos y los coeficientes de cualquier modelo de deriva subyacente. Una vez derivada, la RBF se puede resolver para cualquier punto no muestreado o promediarse sobre cualquier volumen para proporcionar una estimación de grado. Es posible, por ejemplo, consultar la RBF en una rejilla regular para obtener una estimación de los grados de bloque. Dada la facilidad de creación de una RBF y su capacidad para predecir el grado, surge la pregunta de cómo se comparan los grados derivados de la solución de una RBF con las estimaciones de grado derivadas de métodos convencionales de interpolación geoestadística (por ejemplo, kriging ordinario (OK)).
El propósito de este artículo es describir en términos sencillos:
• la estructura básica de una RBF
• el papel de la elección paramétrica en la solución de las RBF y cómo esto influye en el carácter de la solución
• las similitudes y diferencias fundamentales entre las RBF y los estimadores geoestadísticos convencionales.
Utilizando una simulación condicional de alta resolución, se muestra que en muchas situaciones, las estimaciones de la RBF y el OK son muy similares.
INTRODUCCIÓN
En los últimos años, los modelos alámbricos implícitos se han utilizado cada vez más para desarrollar formas 3D coherentes para su uso posterior en la estimación a través de métodos tradicionales (por ejemplo, kriging ordinario (OK)). Cowan et al (2003) introdujeron el término «modelado implícito» en la tarea de modelar geometrías de superficies geológicas. El modelado implícito describe un enfoque del modelado espacial en el que una combinación de datos y controles paramétricos especificados por el usuario definen una función de volumen matemática única. Este enfoque puede aplicarse al modelado de superficies a partir de variables categóricas, como la litología, o al modelado de variables continuas, como leyes geoquímicas en todo el espacio. La función más común actualmente en uso para el modelado implícito es la función de base radial (RBF). El término implícito se usa porque la superficie que se modela existe implícitamente dentro de la función de volumen como una superficie isopotencial definida por los datos en lugar de por un proceso de dibujo explícito. Esta función de volumen puede luego ser cuadriculada, o ‘renderizada’, en una estructura alámbrica para su visualización o posterior uso de modelado.
El método de modelado implícito ahora se usa ampliamente para el modelado de la geometría de la superficie a partir de datos de registro categóricos y para el modelado de «isosuperficies de grado» basadas en variables de grado continuo. Lo que muchas personas desconocen es que los modelos implícitos utilizados para generar «isosuperficies de ley» también pueden proporcionar estimaciones puntuales o de bloque de la ley. En muchas situaciones, son muy similares a las estimaciones obtenidas con métodos de estimación más familiares, como OK. Hay una razón para esto: se puede demostrar (Carr et al, 2001; Chiles y Delfiner, 1999; Costa, Pronzato y Thierry, 1999) que el RBF es matemáticamente equivalente a una formulación particular de kriging (kriging dual (DK) ). En la práctica, las estimaciones derivadas de los RBF también suelen ser muy similares a las producidas por OK.
El propósito de este documento es describir (en términos simples) la estructura básica de un RBF e ilustrar las similitudes que tiene con el kriging. También discutiremos brevemente el papel de la elección de parámetros en la solución de RBF y mostraremos cómo esto influye en el carácter de la solución.
LA IDEA DE LA INTERPOLACIÓN
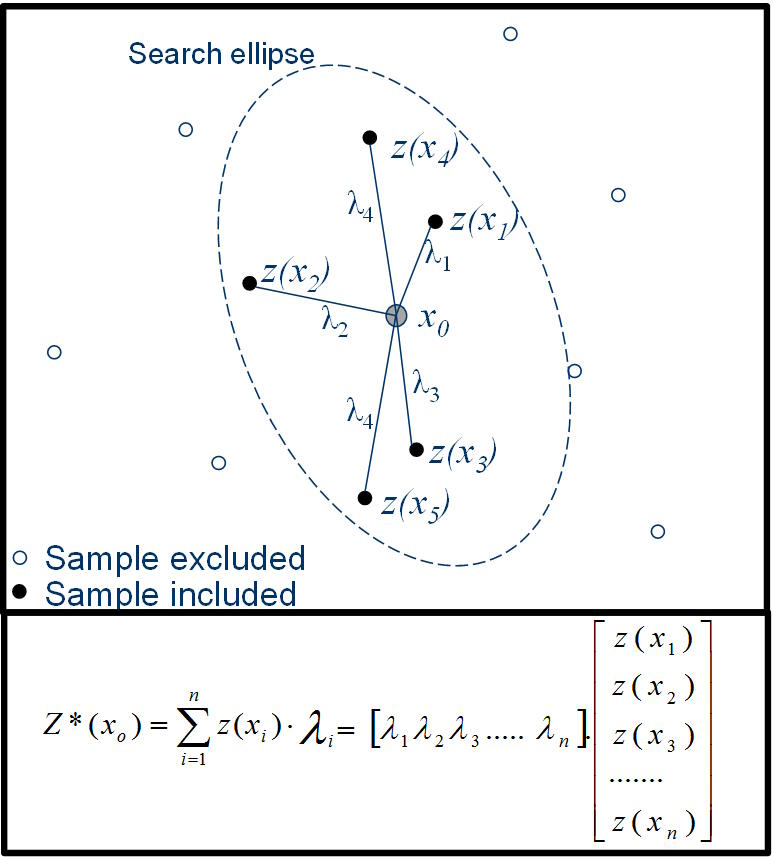
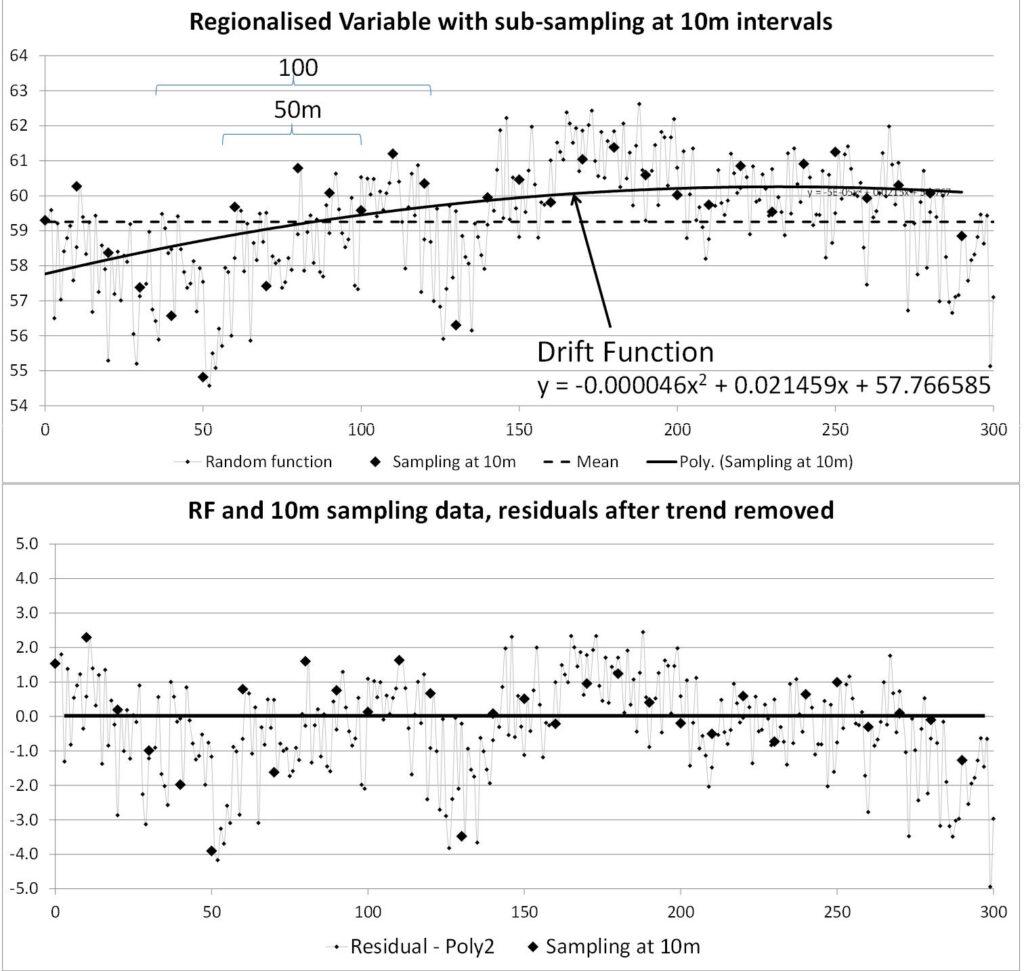
La interpolación es el proceso de predecir (estimar) el valor de un atributo en una ubicación no muestreada a partir de mediciones del atributo realizadas en los sitios circundantes (Figura 1). En la interpolación lineal, la calificación en la ubicación objetivo se calcula como un promedio lineal ponderado de los datos de la muestra. Diferentes interpoladores usan diferentes métodos para determinar el valor de los pesos. Cuando el punto a estimar está dentro del campo de datos disponibles, el proceso se denomina interpolación; cuando el punto está fuera del campo de datos, el proceso se denomina extrapolación. Este proceso puede realizarse en una, dos, tres o cuatro dimensiones. Por lo general, en la estimación de recursos minerales, nos preocupamos por problemas prácticos tridimensionales: predecir la ley de un atributo (por ejemplo, una ley de metal) en ubicaciones no muestreadas a partir de valores medidos en muestras de perforación dispersas. Es una suposición subyacente que el atributo que intentamos predecir es espacialmente continuo, que toma un valor real en todas las ubicaciones posibles. Hay muchas formas diferentes de interpolador posibles. El más básico es el método constante por partes, más conocido como estimación del vecino más cercano, en el que cualquier ubicación no muestreada simplemente toma el valor del punto de datos más cercano. El estimador continuo resultante toma la forma de un patrón de mosaico, con parches de ley constante separados por pasos repentinos. Esta no es una representación muy realista de la forma en que se observa que los atributos reales, como las leyes del metal, varían en la práctica, y otorga pesos significativamente diferentes a las muestras en los extremos espaciales del conjunto de datos. En aras de la simplicidad en la discusión, este documento considerará que el atributo que se predice es el grado de un metal, sin embargo, la idea puede extenderse simplemente a cualquier variable continua.
El interpolador kriging (local)
Los interpoladores se dividen en dos tipos generales: globales o locales. Un interpolador global tiene en cuenta todos los puntos conocidos para estimar un valor, mientras que la interpolación local utiliza un subconjunto de datos, generalmente definido por una vecindad de búsqueda centrada en el punto que se estima.
El interpolador que probablemente se usa más comúnmente en minería es kriging, o más particularmente OK. La idea general es sencilla: la estimación de un punto se basa en una combinación lineal ponderada de valores de datos locales, y los pesos se calculan de tal manera que se minimiza la varianza del error en función de un modelo asumido para la covarianza espacial. Kriging se basa en una serie de suposiciones clave:
La suposición subyacente es que las observaciones de la muestra se interpretan como los resultados de un proceso aleatorio. La variable en estudio (por ejemplo, grado de Fe
s) se puede describir mediante una función aleatoria matemática. Esta conceptualización de los datos es simplemente un ingenioso truco que nos permite describir la realidad como el resultado de un modelo probabilístico.
El paso clave en el modelado geoestadístico es la adopción de un modelo espacial (el variograma) que describe la función aleatoria subyacente. La elección del modelo espacial normalmente se basa en ajustar una función a los datos experimentales disponibles, aunque no existe un vínculo explícito y esta función a menudo se elige más por conveniencia matemática que por derivarse de un análisis del proceso de mineralización.
La adopción de un modelo que resume el proceso aleatorio permite que la varianza del error (la varianza de la diferencia «en promedio» entre la calificación estimada y la verdadera) se exprese en términos de covarianzas espaciales y factores de ponderación aplicados a las muestras (pesos kriging). Las covarianzas espaciales se especifican mediante la elección del modelo de variograma realizado y las ubicaciones de los datos. El álgebra convencional proporciona los medios para encontrar el conjunto de pesos de kriging que minimiza la varianza del error.
Estos atributos son característicos de todos los sistemas kriging. Las variantes más comunes de kriging son kriging simple (SK), OK y kriging universal (UK). Lo que los distingue es la forma en que la variación en la ley media (deriva) se incorpora a los sistemas kriging.
Diferentes sistemas de kriging
Como se explicó anteriormente, lo que distingue a los diferentes sistemas de kriging es la forma en que se incorpora la variación en la ley media (deriva) en los sistemas de kriging.
kriging simple
SK asume que la expectativa de la media (m) es constante en todo el dominio y de valor conocido (estacionariedad intrínseca). Esto equivale a decir que la componente de deriva es constante y conocida. Por lo general, se estima utilizando la media desagregada de los datos muestrales disponibles.
El estimador SK en cualquier punto se reduce a una combinación de dos componentes: un promedio ponderado de los datos locales y la media del dominio. Las estimaciones cercanas a los datos darán más peso a la estimación local, mientras que las estimaciones más alejadas de los datos estarán dominadas por la media del dominio.
SK rara vez se usa en la práctica ya que la suposición subyacente (constante, media conocida) es demasiado severa para la mayoría de las aplicaciones. Además, la incorporación de la nota media como término ponderado en la estimación SK hace que, lejos de la influencia
de datos de la muestra, el estimador vuelve a la nota media. En la mayoría de los depósitos minerales, la ley disminuye hacia el margen y, a menudo, aquí es donde los datos de perforación son más bajos. Tener un estimador que revierte hacia la media en esta región generalmente no es realista.
kriging ordinario
La suposición que distingue a OK de otros sistemas de kriging es que la expectativa de la media es desconocida pero es constante a la escala de la vecindad de búsqueda (una suposición conocida como cuasiestacionariedad dentro de la hipótesis intrínseca). Lo que esto significa en la práctica es que no debería haber tendencias presentes en la calificación media local por debajo de la escala de la búsqueda. Este es un concepto algo resbaladizo ya que es inusual tener una escala clara en la que se aplica esta separación. En la práctica, esto significa que las variaciones en las calificaciones muestreadas presentes dentro de un vecindario local deben ser fluctuaciones aleatorias plausibles en torno a una calificación media local constante, sin que se presente una fuerte tendencia. Esto permite que el sistema OK se adapte a la variación en la media local de modo que la estimación siempre se centre en el promedio ponderado de las muestras presentes en el vecindario local. Esto significa que la especificación de la vecindad de búsqueda local tiene una influencia crítica en la calidad del estimador kriging; en particular, la vecindad debe ser lo suficientemente grande para que los datos contenidos representen adecuadamente la ley media local.
Al extrapolar más allá de los límites de los datos, el estimador OK no revierte hacia la media global, sino que mantiene la media local especificada por las muestras más cercanas.
kriging universal
La teoría de UK fue propuesta por Matheron en 1969 (Armstrong, 1984) para proporcionar una solución general a la estimación lineal en presencia de deriva. Esta teoría asume que la media local es desconocida pero varía de manera sistemática y puede escribirse como una expansión finita de funciones de base conocidas (f) y coeficientes fijos (pero desconocidos) (a). La información de deriva puede entonces incorporarse en la expresión de la varianza de la estimación.
Rápidamente se dio cuenta de que existen graves dificultades prácticas en la implementación del Reino Unido. El desarrollo del sistema del Reino Unido supone que se conoce el variograma subyacente (que incorpora la deriva); en esta situación, el sistema kriging arroja correctamente tanto los coeficientes de deriva como los pesos. En la práctica, sin embargo, el variograma subyacente siempre se desconoce. Esto nos deja con un problema circular; para calcular los residuos necesitamos conocer la deriva,
pero para conocer la deriva necesitamos conocer el sistema del Reino Unido. Esta circularidad no excluye el uso de UK, pero sí significa que se debe tener mucha cautela en su aplicación. Asumir un modelo de deriva y trabajar solo con residuos dará como resultado una estimación sesgada del verdadero variograma subyacente (Armstrong, 1984).
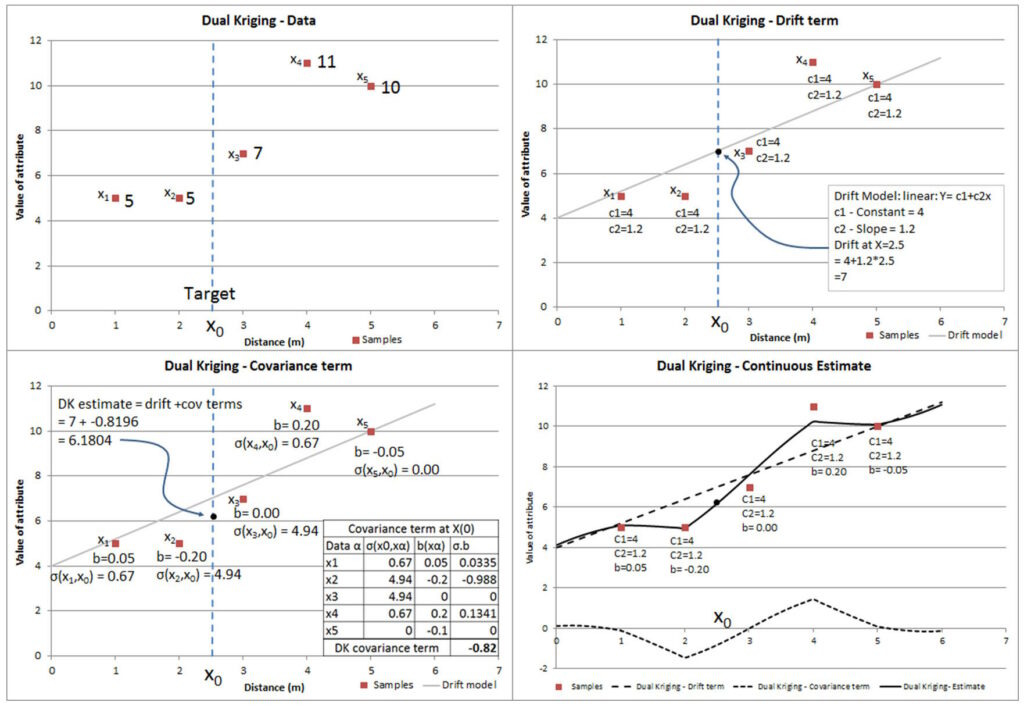
Doble kriging
Los estimadores de kriging discutidos anteriormente se basan en combinaciones lineales de valores de datos de muestra. También es posible reescribir el estimador UK en términos de covarianzas σ(xi,x) y funciones de deriva f l(x) únicamente, omitiendo cualquier referencia directa a los datos. Esto se conoce como DK. El desarrollo no se muestra aquí, pero se da una exposición clara en Chiles y Delfiner (1999) y Galli, Murillo y Thomann (1984). El término ‘dual’ se origina de una derivación alternativa de estas ecuaciones por minimización en un espacio funcional, similar a splines (Chiles y Delfiner, 1999).
Expresado en inglés, la estimación en cualquier punto (x0) es la suma de dos componentes:
Un componente determinista transportado por la suma de los términos de la función de deriva en la ubicación objetivo: c f (x)
Un componente probabilístico calculado como la suma ponderada de las covarianzas entre la ubicación objetivo y todas las ubicaciones de muestra: b v(x ,x)
la función de covarianza (o variograma) es mayor en distancias cortas, es fácil ver que este término será mayor cuando el punto objetivo esté cerca de los datos. Los valores del coeficiente b están influenciados por el agrupamiento y la distancia del valor de la muestra de la ley media local estimada por el modelo de deriva.
La naturaleza de la función de deriva es una elección impuesta por el usuario, y la función de covarianza (o variograma en el caso intrínseco) es igualmente una elección especificada por el usuario. Luego, los valores de los coeficientes b y c se calculan de la misma manera que para otros sistemas de kriging, imponiendo restricciones en el sistema que permiten obtener una solución única (ver Chiles y Delfiner (1999) para más detalles).
Este sistema no es fácil de visualizar. La Figura 3 muestra cómo el estimador DK se compone de deriva y componentes probabilísticos, y que ninguno hace referencia directa a los valores muestreados. Tenga en cuenta que, si bien la estimación de deriva (y los coeficientes) y la estimación probabilística (y los coeficientes) se muestran por separado, en realidad se derivan simultáneamente. La deriva afecta la estimación en todo el espacio, mientras que los coeficientes probabilísticos describen la influencia local alrededor de cada punto de datos.
Una de las principales ventajas del sistema DK es que los coeficientes de deriva y covarianza solo necesitan resolverse una vez y luego pueden usarse para hacer una estimación en cualquier ubicación.
El principal inconveniente del método es que el uso de una vecindad global da como resultado un sistema muy grande de ecuaciones simultáneas, con una ecuación por muestra y una para cada función de deriva.
Funciones de base radial
El RBF es una familia de técnicas matemáticas que se ha aplicado a muchos problemas de interpolación espacial y es la base de la mayoría de los algoritmos de «modelado implícito» que se utilizan en la actualidad. Se basa en una premisa de partida algo diferente a la teoría de las variables regionalizadas en la que se basa el kriging: en lugar de considerar que la variable objetivo es una realización de una función aleatoria con una estructura definida, el RBF se basa en la interpolación de una función predefinida de criterios matemáticos como la minimización de la curvatura. En la práctica, esta diferencia es solo semántica, porque el kriging tradicional también usa determinadas funciones, excepto que estas se ajustan a los datos experimentales y se han elegido para adaptarse al modelado de los datos. Matemáticamente, existe una equivalencia entre DK y el modelado con RBF, y también es posible elegir la función RBF ajustando los datos experimentales. De hecho, debido a que los variogramas como el esférico son definidos positivos (Chiles y Delfiner, 1999, p. 59), son adecuados para usarse como RBF.
El interpolante para un RBF tiene una forma muy similar a la expresión general de kriging: la variable objetivo es se considera que está compuesto por un término de deriva y un término que es un promedio ponderado de los valores de función que dependen de las ubicaciones de los datos.
El término de la derecha se refiere al conjunto de K funciones de deriva (qk(x)), cada una de las cuales tiene un coeficiente (ck) aplicado globalmente a todos los datos.
De la misma manera que para DK, se imponen condiciones que hacen que el sistema sea solucionable. En este caso, las condiciones son que: el producto de los coeficientes RBF y los coeficientes de la función de deriva en cada punto de datos debe sumar cero en todos los puntos de datos, y la función debe devolver el valor de los datos en un punto de datos (ver Cowan et al. (2001) para detalles y Chiles y Delfiner (1999) para el ejemplo paralelo de DK). Estas condiciones permiten expresar el sistema como un conjunto de ecuaciones lineales. Esto se muestra en forma de matriz de la siguiente manera:
Accede al articulo completo en nuestra biblioteca Digital.
Las reservas de mineral son parte de los recursos minerales que son económicamente viables para su extracción utilizando la tecnología actual. Para la reserva de mineral, la ley y el tonelaje deben establecerse con una seguridad razonable mediante perforación y otros medios.
¿Cuál es la diferencia entre recurso mineral y reserva de mineral?
Los Recursos Minerales se definen como la concertación de material de interés económico en la corteza terrestre. Las reservas de mineral son aquellas partes de los Recursos para las que se han establecido la ley y el tonelaje con una seguridad razonable mediante técnicas de muestreo del subsuelo y se pueden extraer de manera rentable utilizando la tecnología actual.
Definición de Estimación de Reservas
La estimación de reservas es la cuantificación del material económico presente en el yacimiento con una precisión razonable. También implica el cálculo de ley, espesor y diferentes parámetros cualitativos que se requieren para la explotación comercial del mineral.
¿Cuáles son las formas de estimación de reservas de mineral?
Los métodos de estimación de reservas de mineral se pueden agrupar de tres maneras:
Método Geométrico (Método Convencional)
Método Estadístico o Geoestadístico
aplicación informática o software
¿Cuál es el principio básico de la estimación de reservas de mineral?
El principio básico de la estimación de reservas de mineral es utilizar la fórmula de tonelaje. La unidad de estimación es la tonelada (t) y la fórmula es:
Tonelaje (t) = Volumen (V) x Gravedad específica (densidad aparente)
La ecuación anterior se puede comparar con la fórmula de volumen de masa donde:
Masa = Volumen x Densidad
El volumen se puede calcular como:
Volumen (V) = Área (A) x Influencia de una tercera dimensión
El área (A) se calcula a partir del plano o secciones del pozo.
La influencia se determina en función del método de estimación.
Supuestos básicos: se toman varios supuestos para la estimación de reservas. Ellos son –
Los parámetros de un cuerpo de mineral establecidos en un punto cambian a un punto contiguo de acuerdo con cierto principio como regla de cambios graduales, regla de puntos más cercanos.
La continuidad proyectada del cuerpo mineral basado en datos de exploración se supone por configuración geológica.
Las muestras se recolectan con igual precisión en cada punto y representan la zona del mineral.
En este artículo discutiremos solo los métodos convencionales de estimación de reservas de mineral. Existen muchos métodos de cálculo basados en la anisotropía, el patrón de cuadrícula de perforación y la etapa de exploración.
método poligonal
método triangular
Método de la sección transversal
Método de distancia inversa
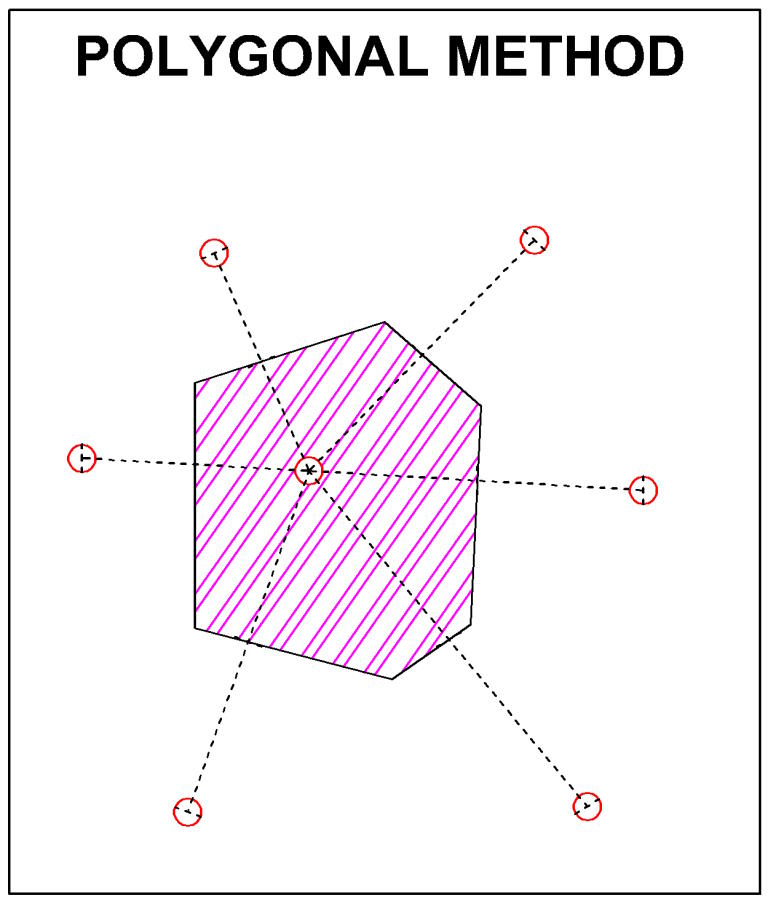
Método poligonal
El método se basa en el área de influencia. El área de influencia se determina construyendo bloques poligonales alrededor de cada agujero que se extienden a la mitad de la distancia entre dos agujeros. La ley y el espesor promedio del agujero dentro del polígono se asignan a todo el polígono para proporcionar un volumen para la estimación de la reserva. El volumen se calcula multiplicando el área de los polígonos por el grosor. El volumen se multiplica por la gravedad específica para obtener el tonelaje. La suma de todos los polígonos obtendrá el tonelaje y el contenido de metal del depósito total.
El método poligonal se utiliza para cuerpos de mineral de lentes tabulares y grandes.
Las desventajas de este método son:
Da mayor peso al hueco aislado.
Los valores de ensayo se utilizan una sola vez.
Una variante del método poligonal que utiliza valores de agujeros en las esquinas de los polígonos en lugar del centro. Se discutirá como método triangular.
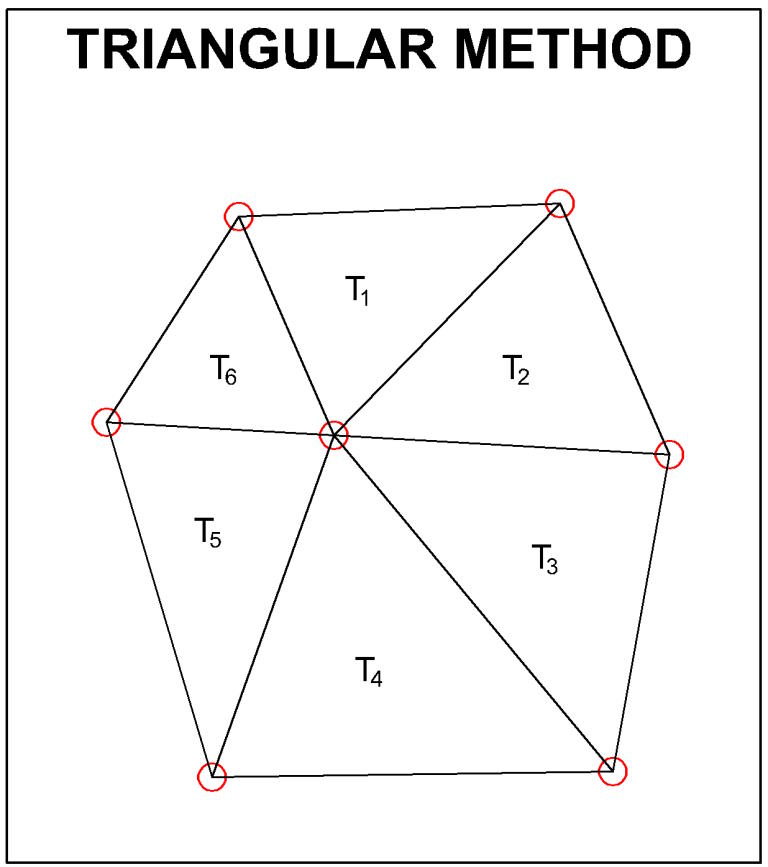
método triangular
Este método es una versión ligeramente avanzada del método poligonal. En este método, los agujeros se conectan a agujeros adyacentes. Esto divide el cuerpo mineralizado en una serie de triángulos (T 1 , T 2 , – – – – – -, T n ). Cada triángulo descansa sobre el plano del mapa y representa un área base de un prisma imaginario con bordes t 1 , t 2 , t 3 iguales a los espesores verticales de mineralización interceptada. En este método, el área del triángulo entre tres barrenos adyacentes, la ley promedio y el espesor de estos barrenos se utilizan para calcular el tonelaje.
Pasos de cálculo
Los siguientes pasos están involucrados en el método triangular:
El área del triángulo se calcula usando la fórmula geométrica. El área (A) se multiplica por el espesor promedio interceptado en los agujeros en los tres bordes de ese triángulo para obtener el volumen (V).
El tonelaje se calcula multiplicando el volumen (V) por la gravedad específica promedio de la roca huésped. Esto dará el tonelaje de un triángulo.
El contenido de metal se estima multiplicando el tonelaje (paso 2) y la ley promedio.
Los pasos 1 y 2 se repiten para todos los triángulos con intersecciones positivas en sus bordes.
El tonelaje total y el contenido de metal del depósito se obtienen sumando los valores calculados para cada triángulo.
El método triangular es el más adecuado para cuerpos de mineral de inmersión plana o suave que tienen buena continuidad y correlación.
Las diferentes fórmulas involucradas en el cálculo son:
La hoja de datos del método triangular se verá a continuación:
Método de la sección transversal
En este método, el cuerpo del mineral se interpreta en la sección transversal. El cuerpo de mineral se divide en diferentes segmentos con la ayuda de líneas de sección transversal. La línea de sección puede ser espacios a intervalos iguales o desiguales según el intervalo de cuadrícula y las ubicaciones de los agujeros.
Secciones transversales que muestran el yacimiento en tercera dimensión
Pasos de cálculo
El cuerpo mineral total se divide en sub-bloques a lo largo de la línea de sección y una longitud igual a la mitad de la distancia entre las secciones contiguas.
Para el cómputo de la reserva se requiere el volumen de cada subbloque. El volumen se calcula multiplicando el área de la sección por la mitad de la distancia de la sección contigua a cada lado (es decir, el área de influencia).
El área de la sección del cuerpo mineralizado se calcula mediante una fórmula geométrica. El software AutoCAD se puede utilizar para medir el área de un cuerpo de mineral irregular.
El tonelaje de cada subbloque se calcula multiplicando el volumen y la gravedad específica.
El contenido de metal de cada subbloque se calcula multiplicando el tonelaje y la ley promedio de ese subbloque.
El tonelaje total del cuerpo mineralizado es la suma de los tonelajes de los subbloques. De manera similar, el contenido de metal total es la suma de los contenidos de metal del subbloque.
La ley promedio del cuerpo de mineral es el contenido total de metal dividido por el tonelaje total en términos porcentuales.
La hoja de datos del método de sección transversal se verá a continuación:
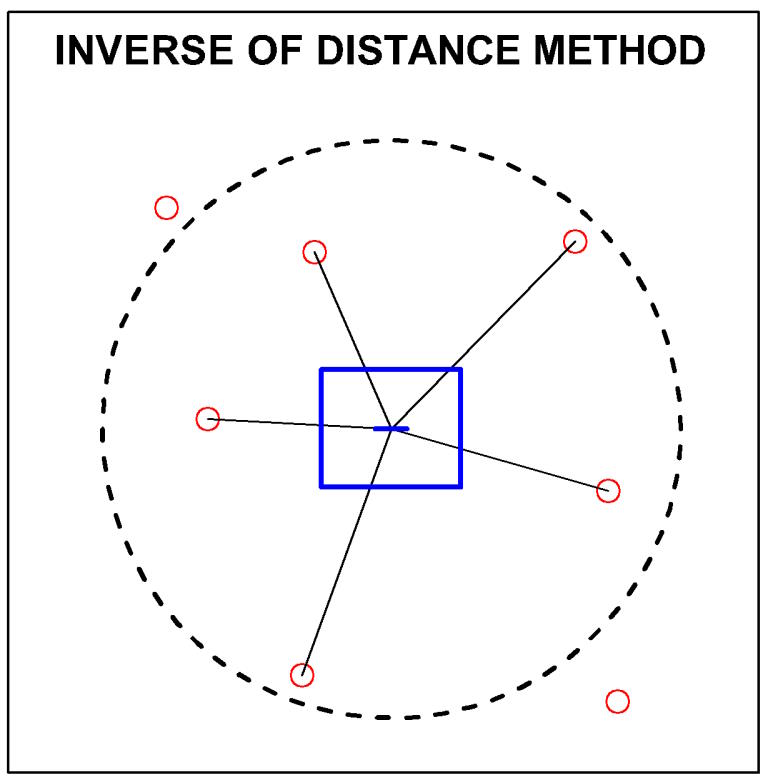
Método de distancia inversa
El método de distancia inversa pertenece a la clase de métodos de promedio móvil. Se basa en cálculos repetitivos y, por lo tanto, requiere el uso de computadoras. En este método, el peso del agujero se da de acuerdo con la distancia desde el bloque en el que se va a realizar el cálculo. Se otorga más ponderación al orificio más cercano en comparación con los otros orificios de la región.
Principio del método de distancia inversa considerando
muestras que caen dentro del círculo de búsqueda o elipse en dos
dimensiones.
Selecciona solo aquellos agujeros que caen dentro de la zona de influencia. El método de distancia inversa utiliza el principio de que la variable de los pozos adyacentes tiene cierta relación espacial y esta relación es una función de la distancia.
A diferencia del método de polígono, el método de distancia inversa utiliza los valores de todos los agujeros circundantes según ciertos pesos. Los pesos están determinados por la distancia entre los agujeros y el centro del bloque considerado para el cálculo. La suma de todos los pesos debe ser uno.
La ponderación de los valores puede ser de orden uno (inversa a la distancia), orden dos (inversa al cuadrado de la distancia), etc. Este método ignora la anisotropía direccional en el esquema de ponderación.
El método de distancia inversa se puede aplicar a depósitos con geometría simple a moderada y con variabilidad de ley baja a alta.
Para acortar la longitud del artículo, he discutido solo métodos convencionales seleccionados aquí. En mi otro artículo en este blog, he discutido el método de estimación geoestadística de reservas de mineral .
Un modelo de bloques es una representación simplificada de un yacimiento mineral y sus alrededores, que se puede considerar como una pila de «ladrillos» generados por computadora que representan pequeños volúmenes de roca en un depósito (compuesto por mineral y desechos). Cada «ladrillo» o celda contiene estimaciones de datos, como la ley del elemento, la densidad y otros valores de entidades geológicas o relacionados a factores de ingeniería.
Las celdas de un modelo de bloques están dispuestas en un sistema de cuadrícula XYZ, y las celdas pueden ser de tamaño uniforme o irregular. En estos paquetes, a los bloques se les asigna una calificación mediante uno de varios métodos de estimación diferentes: distancia inversa al cuadrado, kriging ordinario, kriging de indicadores múltiples, etc.
MARCO DE REFERENCIA DEL MODELO (MODEL FRAMEWORK)
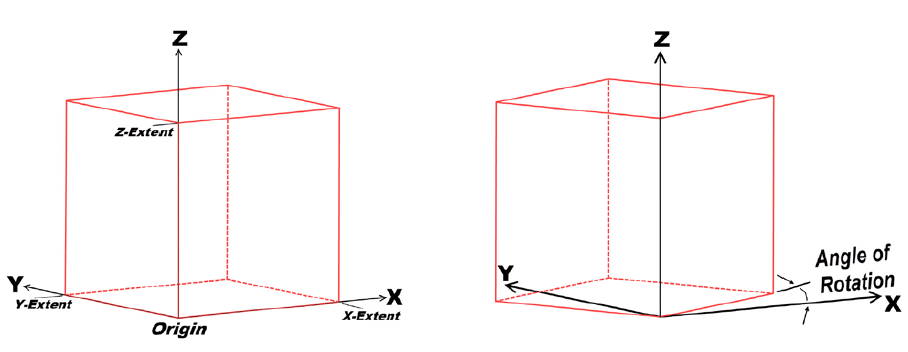
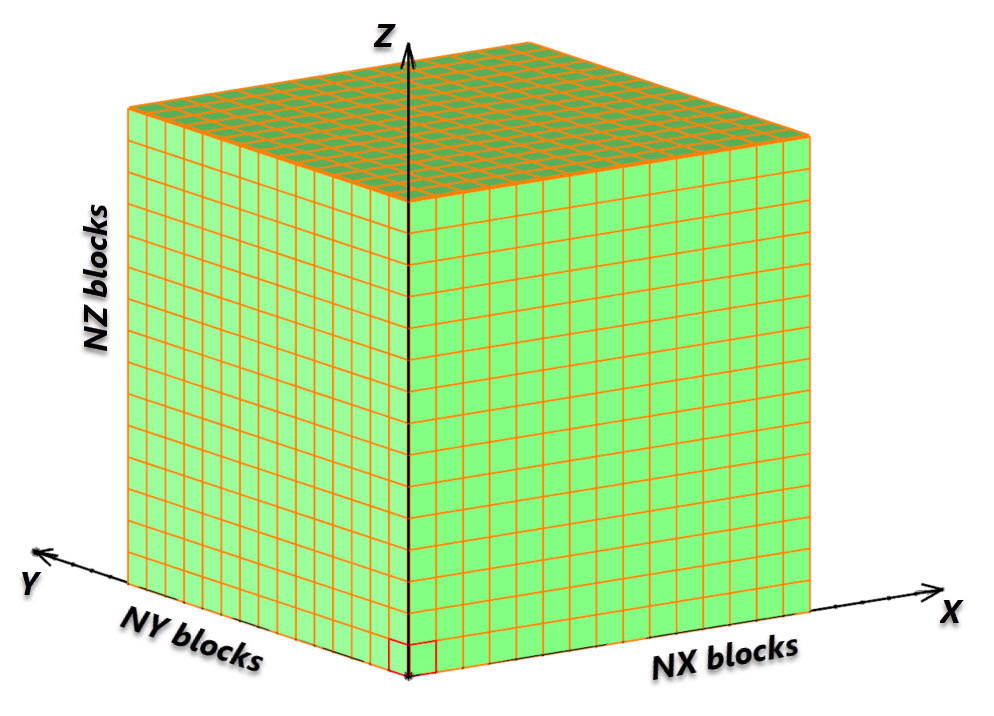
El término «model framework» define la región rectangular del espacio dentro de la cual se ubican las celdas del modelo. Requiere un origen, distancia para cada eje y ángulo de rotación.
Marco de referencia de modelo de bloques estándar
Dentro de este marco hay bloques individuales, todos con una longitud designada (incremento X), anchura (incremento Y) y altura (Z-incremento). La posición del bloque puede ser definida por un centroide (Xc, Yc, Zc) o un origen de bloque (Xmin, Ymin, Zmin).
Definición de bloque de modelo de bloque
El número de bloques en cada dirección del eje de coordenadas generalmente se especifica para definir el marco del modelo de potencial completo. Tenga en cuenta que algunos esquemas de modelado no necesariamente necesitan un modelo de bloques completamente «lleno»: los bloques pueden faltar o estar ausentes dentro del marco.
Modelo de bloques rellenos
El número de bloques en cada dirección del eje de coordenadas generalmente se especifica para definir el marco del modelo de potencial completo. Tenga en cuenta que algunos esquemas de modelado no necesariamente necesitan un modelo de bloques completamente «lleno»: los bloques pueden faltar o estar ausentes dentro del marco.
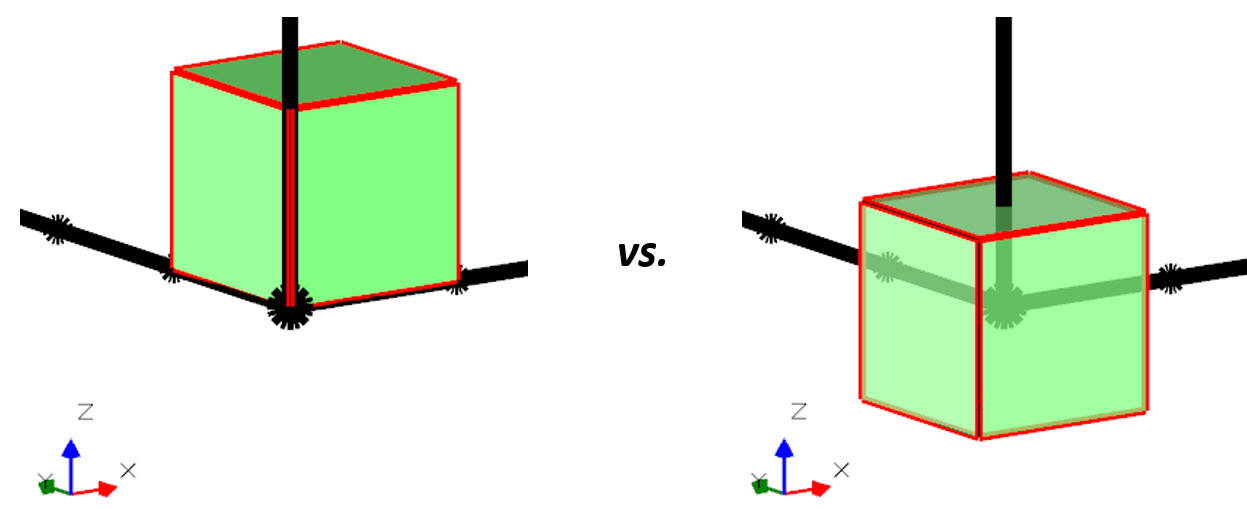
Relación entre el centroide del bloque potencial y el origen
Un aspecto final e importante de los marcos de modelos de bloques es observar cómo se colocan los bloques en el origen. Hay dos opciones. El formato de bloque con el «bloque de origen» ubicado a lo largo de los ejes, es el más común, pero el «bloque de origen» tiene su centroide ubicado en el origen. debe verificarse, ya que a veces ocurrirá.
Proxima entrega: Sub celdas y modelos rotados (siguenos en nuestro canal de Youtube y en nuestra pagina de Facebook)
Esto está escrito para aquellos que tienen problemas para modelar vetas con datos fragmentados, especialmente muestras de canales.
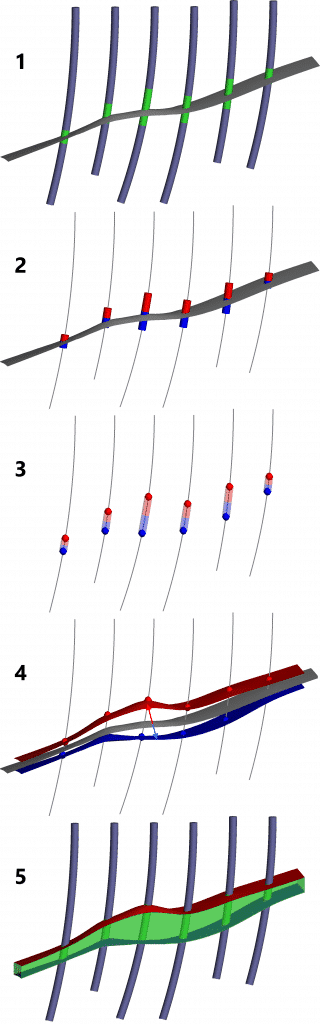
La herramienta de vetas de Leapfrog Geo fue diseñada para trabajar con datos de sondajes, idealmente perforaciones que intersecan ambas paredes de la estructura de veta tabular. Si está utilizando la herramienta de modelado de vetas con datos de muestra de canal fragmentados, encontrará útiles estos consejos y trucos. Cómo funciona la herramienta de vetas Para empezar, vale la pena comprender cómo funciona la herramienta de vetas. Consulte la figura 1 a continuación.
1. Primero, se genera una superficie de referencia a partir de los puntos medios de los intervalos de las vetas. 2. A los segmentos de veta se les asignan lados de pared colgante (HW) y pared de pie (FW) según su orientación a la superficie de referencia. 3. Se generan puntos HW y FW separados en los extremos de estos segmentos. 4. Se generan las superficies HW y FW; ambas son compensaciones de la superficie de referencia que se ajustan a los puntos respectivos. 5. El producto final es el volumen encerrado entre las superficies HW y FW.
Clasificación del segmento de veta
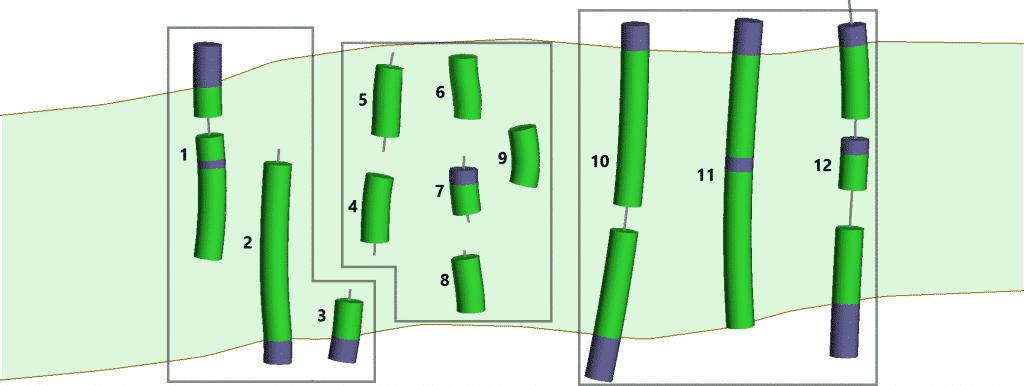
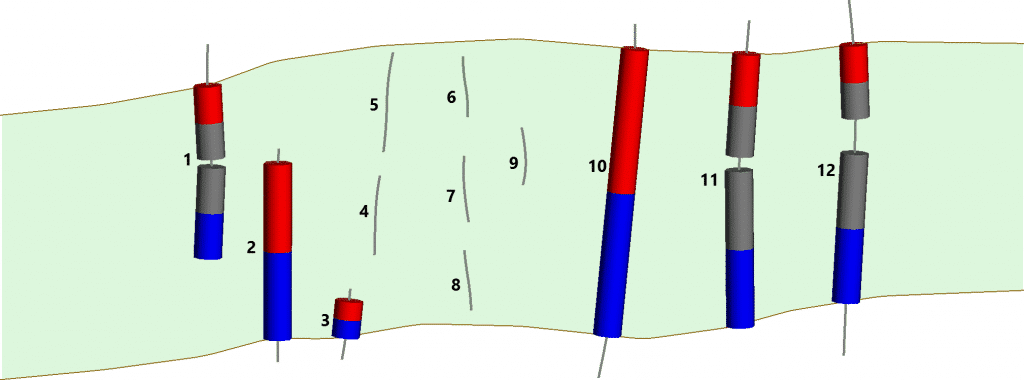
Debido a la forma en que Leapfrog Geo clasifica automáticamente los segmentos de vetas, podemos definir tres tipos básicos de muestras de vetas. • Las muestras de pared a pared están en el mismo agujero o canal y representan / tocan / intersecan ambas paredes de la verdadera estructura de la veta. • Las muestras de vetas incompletas son muestras que representan solo una pared de la verdadera estructura de la veta. • Las muestras de vetas internas no se cruzan con ninguna de las paredes verdaderas de la vena.
Figura 2. Grupos: Derecha = muestras de pared a pared, Izquierda = muestras incompletas, Centro = muestras internas
La estructura de la veta ‘verdadera’ está representada por el color verde claro, con las paredes representadas por las líneas marrones. Los intervalos verdes representan muestras de vetas registradas, los intervalos violetas representan muestras de «vetas externas» registradas, las líneas grises representan las secciones no muestreadas del pozo o canal.
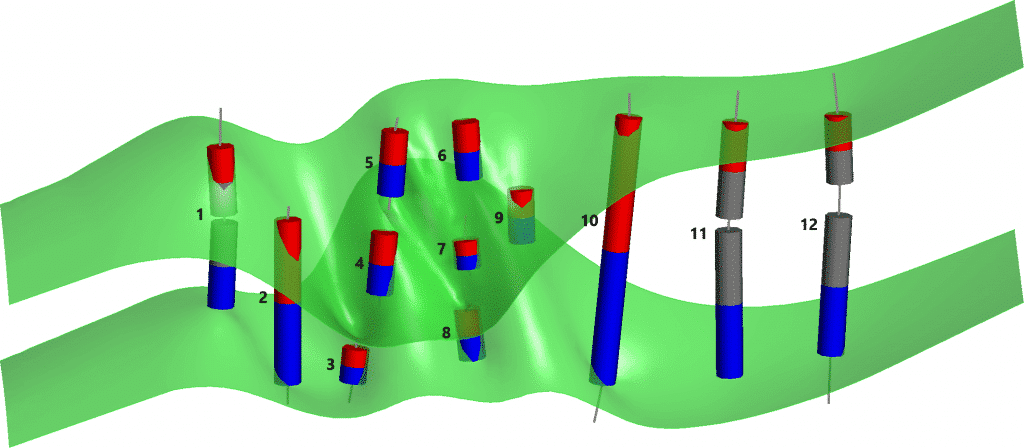
Como puede ver en las figuras 3 y 4, la clasificación automática de segmentos de vetas de Leapfrog Geo hace un buen trabajo con tipos de muestras de pared a pared, incluso cuando están muy fragmentadas como el último hoyo, pero no funciona tan bien con los tipos de muestra incompletos y tipos de muestras internas. Estos tipos de muestras internas e incompletas pueden producir triangulaciones superficiales deficientes porque las superficies están en contacto con cada uno de sus respectivos puntos finales de segmento. Las superficies de la pared colgante y la pared del pie pueden cruzarse entre sí, generando agujeros en el volumen modelado de la veta.
Figura 3. Resultados de la clasificación automática de segmentos de vetas de Leapfrog Geo. Cada extremo de segmento está representado por uno de estos tres tipos: Muro colgante (rojo), Muro de pie (azul) y Excluido (gris). Las triangulaciones de la superficie de la pared de la vena resultantes son verdes en esta imagen.
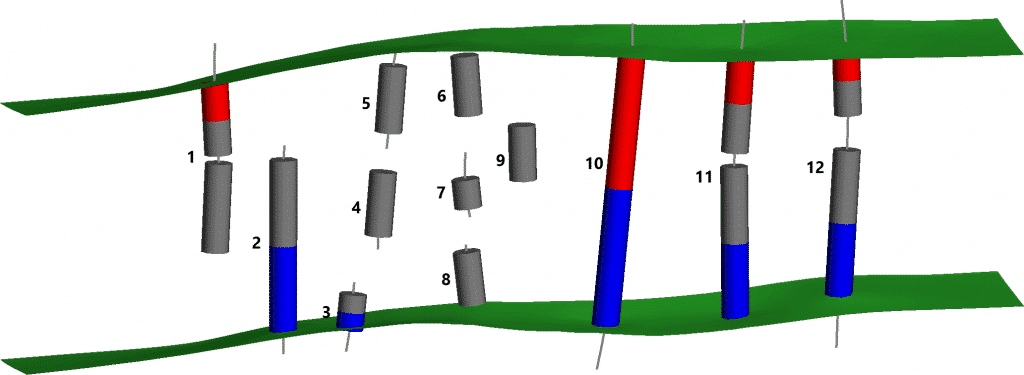
Figura 4. La clasificación ideal de estos segmentos de vetas. Todas las muestras internas se clasifican como «Excluidas». Se excluyen los extremos internos de los segmentos incompletos.
Edición manual
Con algunas ediciones manuales, puede lograr la clasificación de segmento de vena ideal en Leapfrog Geo.
Editar segmentos de vetas
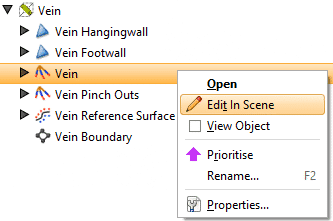
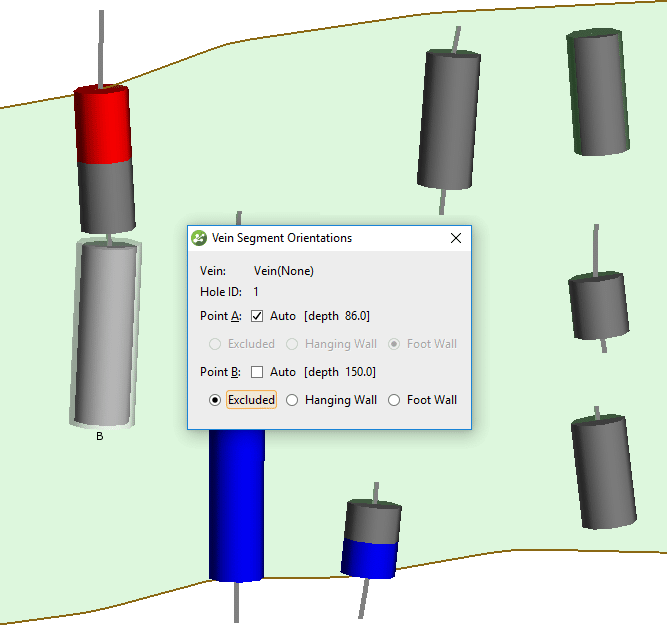
Para corregir los segmentos de vena en las muestras incompletas, deberá editar manualmente los segmentos de vena y anular sus clasificaciones automáticas. Haga clic con el botón derecho en los segmentos de la vena y seleccione Editar en escena (ver figura 5).
Figura 5. Para editar segmentos de vena, haga clic con el botón derecho en el objeto de segmentos de vena debajo de la vena en el árbol del proyecto.
Haga clic en un segmento de vena, luego en el cuadro de diálogo Orientaciones de segmento de vena desmarque Auto para el punto (A o B) que es incorrecto. Fije el punto a la clasificación correcta. En el ejemplo ilustrado en la figura 6, el punto A del segmento parcial ha sido excluido por lo que será ignorado por las superficies de la pared de la veta. Repita esto para todos los segmentos de vena clasificados incorrectamente de muestras parciales.
Figura 6. Anule manualmente la clasificación de segmentos de vetas.
Ignorar muestras internas
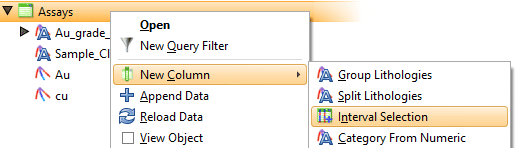
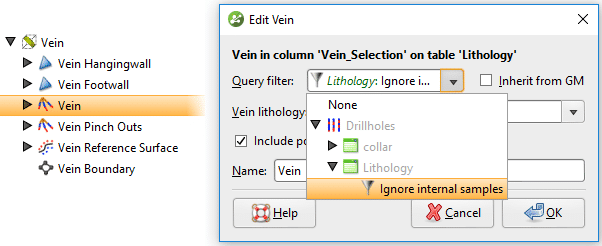
Puede llevar mucho tiempo anular manualmente la clasificación del segmento de vena, especialmente con muestras de vetas internas que deben tener ambos extremos de segmento (punto A y punto B) excluidos. Una forma de evitar esto es ignorar estas muestras con un filtro de consulta. Primero, deberá clasificar las muestras internas en la tabla de intervalos. Luego, cree una nueva selección de intervalo en la tabla de intervalos a partir de la cual se construyó su vena (consulte la figura 7).
Seleccione y asigne todas las muestras internas a un nuevo código de ‘litología’ (ver figura 8)
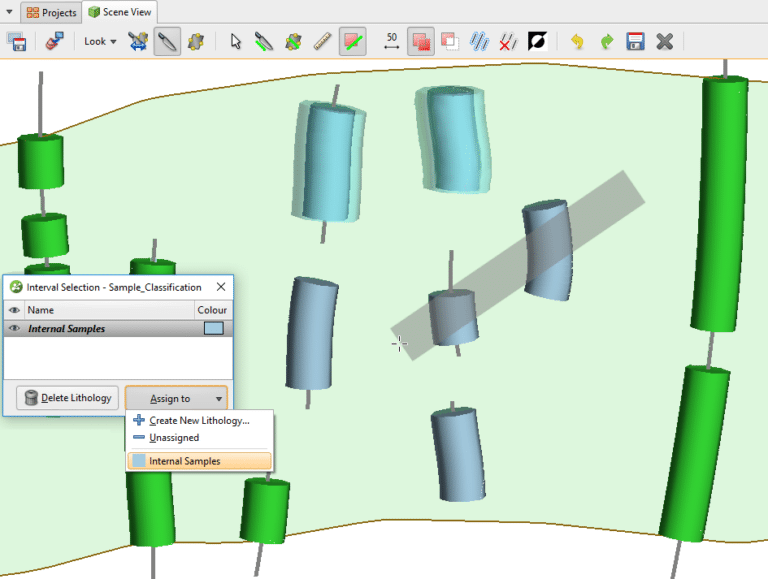
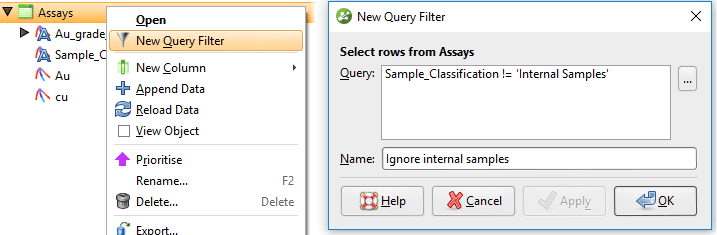
Una vez que se crea la columna de selección de intervalo, en la misma tabla de intervalo, cree un nuevo Filtro de consulta que ignore las muestras internas.
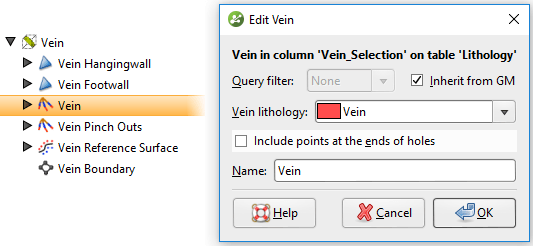
Figura 9. Cree un nuevo filtro de consulta que ignore las muestras de vetas internas. Para aplicar este filtro de consulta a la vena, abra los segmentos de la vena, desmarque la opción para heredar el filtro de consulta del GM (modelo geológico) y seleccione el nuevo filtro de consulta de la lista desplegable
Figura 10. Aplique un filtro de consulta a los segmentos de vena para ignorar las muestras internas.
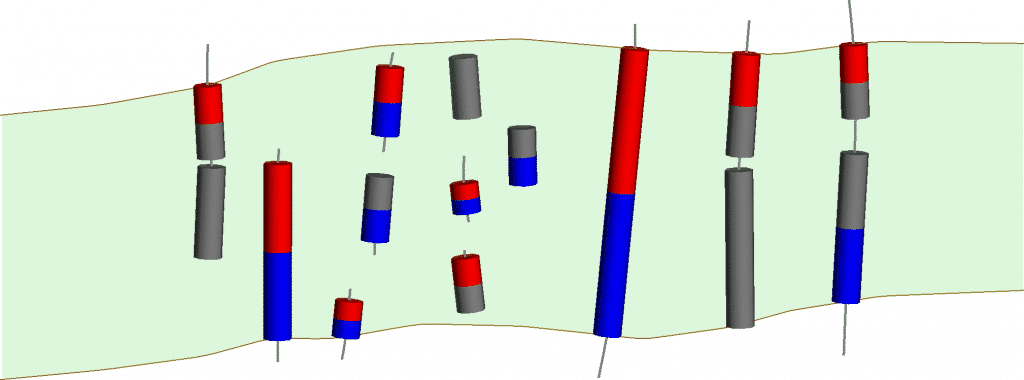
Figura 11. Resultados de la clasificación de segmentos de vetas de Leapfrog Geo después de ignorar las muestras internas
Ignorar puntos al final de los agujeros
Dependiendo de los datos, es posible reducir el número de ediciones manuales excluyendo automáticamente los extremos del segmento al final de un agujero o canal. La configuración predeterminada para los segmentos de veta es incluir puntos al final de los agujeros. Para cambiar esta configuración, abra los segmentos de la vena haciendo doble clic (o haga clic con el botón derecho y seleccione Abrir), resaltados en naranja en la imagen, luego desmarque la opción para incluir puntos en los extremos de los agujeros (ver figura 12).
Figura 12. Desmarque la opción para incluir puntos en los extremos de los agujeros.
Figura 13. La clasificación automática de segmentos de veta que excluye puntos en los extremos de los pozos.
Como puede ver en la figura 13, los extremos de los segmentos de veta se excluyen al final de los orificios o canales. Esto ha resuelto el problema de clasificación de algunas de las muestras internas e incompletas. Sin embargo, si hay muchas muestras de vetas que se extienden hasta el final de los orificios (p. Ej., El orificio 11), o si la vena representa un caparazón de grado que debe encerrar firmemente todas las muestras de vetas, es posible que cambiar este ajuste no siempre sea apropiado
Conclusión
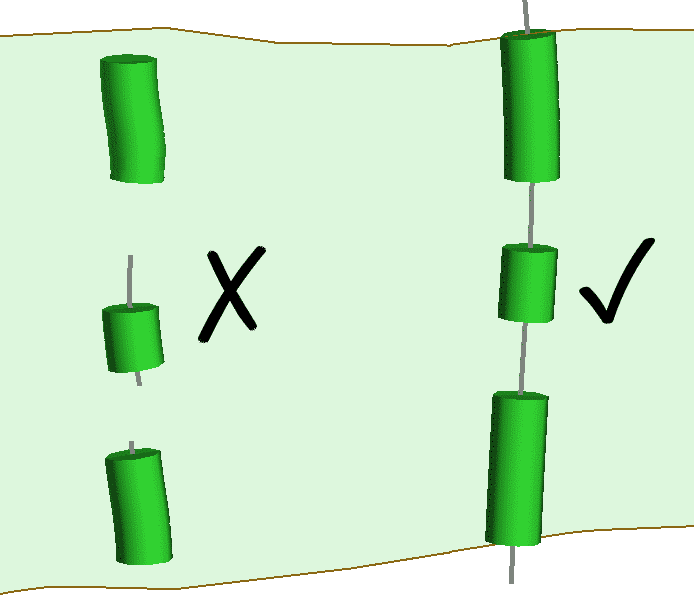
Con respecto a la clasificación automática de segmentos de vetas de Leapfrog Geo, el tipo de muestra de veta más recomendado para usar es de pared a pared. Incluso si el muestreo de pared a pared está fragmentado (separado por intervalos no registrados o intervalos sin vetas), la clasificación automática de segmentos producirá resultados apropiados. Con las muestras de canal, si las muestras de vena se pueden incluir en el mismo canal continuo, perpendicular a la estructura de veta tabular, puede minimizar o eliminar la necesidad de ediciones manuales en Leapfrog Geo (figura 14).
Figura 14. Muestras de canales fragmentados. Las muestras de la izquierda deberán editarse manualmente para producir una triangulación de vena razonable, mientras que las muestras de la derecha funcionarán automáticamente
Fuente: Leapfrog Geo
🚀 Aprende sin límites
📚✨ Ahora todos nuestros cursos exclusivos están disponibles en YouTube Miembros y Patreon.
Únete hoy y accede a contenido avanzado, guías especializadas y soporte directo. 🎥🔥