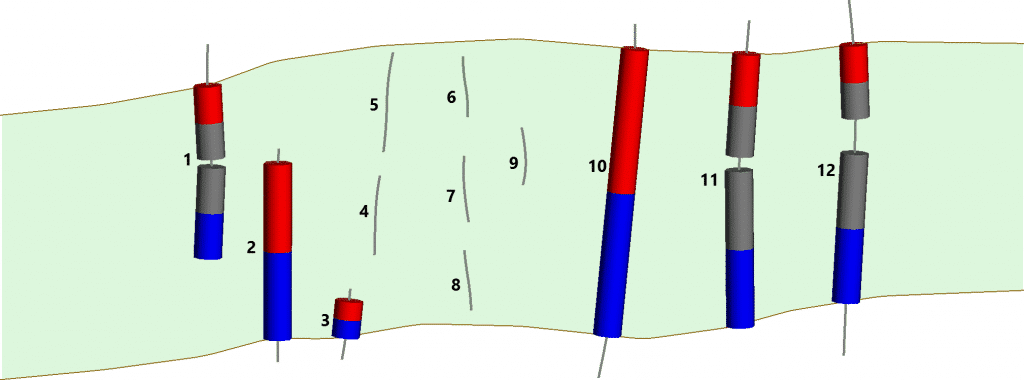
El logueo (ingles: log, logging) se refiere al mapeo o registro de los testigos de perforación, sean estos fragmentos o núcleos cilíndricos. Las perforaciones se realizan para extraer información de diferentes profundidades. En exploración, estos son programados según la interpretación basada en la geología de la superficie, resultados de muestreo geoquímico, prospección geofísica. Las interpretaciones son realizadas tanto en secciones verticales como en secciones horizontales, así poder tener una visión tridimensional.
Existen diferentes métodos de perforación, en exploraciones mayormente se realizan dos métodos: perforación diamantina (diamond drill hole, DDH) y perforación de aire reverso (reverse circulation drilling, RC). En el caso de perforación diamantina, se extrae un testigo o núcleo de roca. Pedazos pequeños de roca, si la perforación es por el método de circulación de aire reverso (RC).
Caja de testigo de perforación diamantina, cada medida corresponde a un tramo de perforación. En este tipo de caja la medida de canal es de 1 metro.Foto de caja de fragmentos extraidos de perforación por circulación reversa. En este caso se observan medidas de los tramos en la parte superior y anotaciones posteriores indicadas de resultado de muestreo.
Como se puede asumir, un núcleo cilíndrico de sondaje nos brindará la mayor información geológica: textura litológica, estructuras, etc. El primer paso de un buen registro de testigos de roca corresponde a las mediciones de recuperación, si bien muchas veces es realizado a pie de maquina (en plataforma de perforación), debe ser siempre verificado revisando que las piezas encajen correctamente, al extraer el núcleo de roca en perforación diamantina, este puede estar fracturado o ser masivo. Cuando está fracturada la roca puede tener perdidas en la recuperación, es decir, lo extraído por la perforación no tiene la misma medida que lo perforado. La poca recuperación de un testigo es una perdida de información. El porcentaje de recuperacion se registra en porcentaje.
% recuperacion = (longitud medida del tramo / longitud de perforación) x 100
Evitar las perdidas de testigos de roca debe ser una de las prioridades en la perforación aunque es difícil evitar en terrenos fallados o fracturados, se debe minorizar dentro de la operación. Un método de control de la operación realizada por los perforistas es medir las recuperaciones cada extracción de testigo (corrida, tramo de perforación).
El logueo geológico puede dividirse en dos tipos: logueo rápido y el logueo detallado. El logueo rápido sirve para entregar información resaltante y resumida de manera inmediata indicando la unidad litológica, la presencia o ausencia de mineralización y alteración, donde el objetivo es entregar información para toma de decisiones. En cambio, en el logueo detallado, las unidades deben ser descritas de forma mas profunda, es decir, indicando las características generales y únicas de cada tramo, especificando grados de alteración y mineralización, midiendo los ángulos de fracturamiento y su intensidad, al igual que las venillas presentes. El registro se puede realizar en forma de códigos y nomenclaturas que son definidas por la empresa o por las necesidades propias del proyecto.
Pasos generales para realizar un logueo geológico. Desde que este es extendido para revisar sus caracteristicas:
Identificar la roca. Color, textura, minerales componentes, etc.
Reconocer estructuras. Reconocer las discontinuidades de la roca como son las fallas, fracturas, venillas.
Definir la alteración. Se debe reconocer los minerales que estén presentes y definir si pertenecen a una alteración. Las alteraciones mas recurrentes es la propilitización, silicificación, sericitización, etc.
Definir contactos. El testigo de perforación puede extraer diferentes unidades de roca y alteración, por lo tanto, existen contactos entre estas diferentes unidades. Definir si el contacto entre las rocas es gradual o definido es primordial para la descripción. Marcarlos es un buen paso para diferenciar las unidades en el registro que se realiza.
Medir las observaciones. Las diferencias entre tramos observado por presencia de contactos o por la aparición de una nueva caracteristica, debe ser acotado y medido. Definir donde comienzan y terminan estas observaciones geológicas, es decir medir los tramos de testigo.
El paso final es describir estas observaciones en las hojas de logueo, se debe realizar de manera clara que pueda ser entendida por los demás geólogos. La manera de estandarizar será según el formato que cada empresa. Estos podrán necesitar gráficos o codificaciones, por lo tanto, entender bien las nomenclaturas y protocolos de logueo de la empresa contratante es uno de los pasos mas importantes, pues uno tiene el conocimiento geológico pero como registrarlos depende de cada empresa.
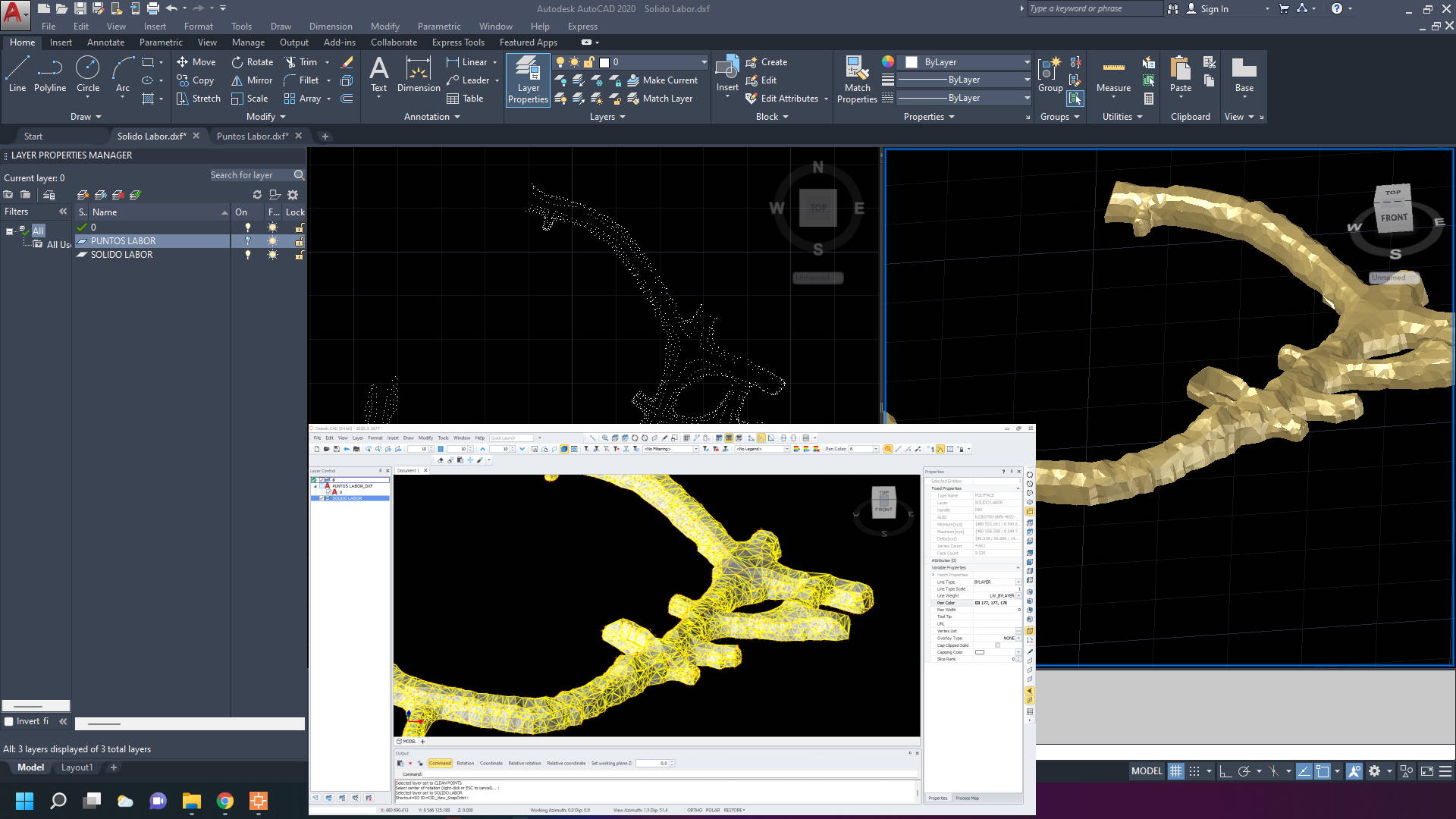
Cuando se generan sólidos de labores mineras con algún software, este sólido puede contener errores como espacios vacíos, overlappings, aberturas, etc. Lo cual genera problemas para poder calcular volumen o tonelaje..
En este Tutorial rápido, mostraremos una forma rápida de corregir esos errores, así como generar sólidos de labores mineras a partir de puntos topográficos.
Puedes descargar los archivos usados en nuestro centro de descarga:
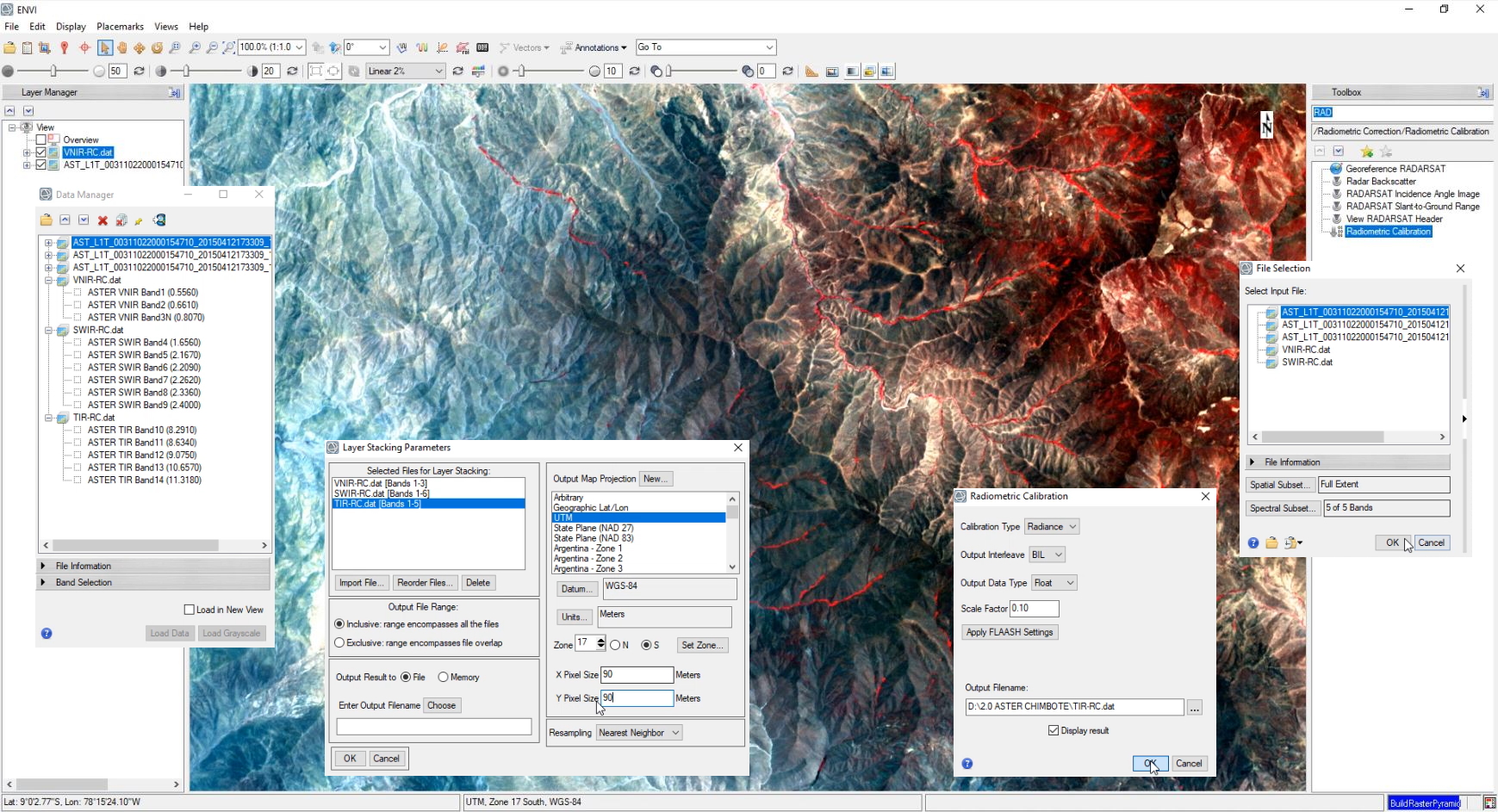
La calibración de imágenes es un paso previo al procesamiento común para los analistas de teledetección que necesitan extraer datos y crear productos científicos a partir de imágenes. La calibración intenta compensar los errores radiométricos de los defectos del sensor, las variaciones en el ángulo de escaneo y el ruido del sistema para producir una imagen que represente la radiación espectral verdadera en el sensor.
La herramienta de calibración radiométrica de ENVI ofrece opciones para calibrar las imágenes según las temperaturas de resplandor, reflectancia o brillo. Las opciones de calibración disponibles dependen de los metadatos que se incluyen con las imágenes.
Layer Stacking
Utilice Layer Stacking para crear un nuevo archivo multibanda a partir de imágenes georreferenciadas de varios tamaños, extensiones y proyecciones de píxeles. Las bandas de entrada se volverán a muestrear y volver a proyectar a una proyección de salida y tamaño de píxel seleccionados por el usuario. El archivo de salida tendrá una extensión geográfica que abarque todas las extensiones del archivo de entrada o abarque solo la extensión de datos donde todos los archivos se superponen.
En esta oportunidad compartimos con ustedes un tutorial para la importación y la visualización de datos geofísicos usando Leapfrog Geo si tienen dudas o consultas pueden usar nuestro foro.
El modelado implícito es un enfoque de modelado espacial en el que la distribución de una variable objetivo se describe mediante una función matemática única que se deriva directamente de los datos subyacentes y los controles paramétricos de alto nivel especificados por el usuario. Este enfoque de modelado se puede aplicar a variables discretas como la litología (después de convertir los códigos discretos en valores numéricos) o a variables continuas como las leyes geoquímicas. Este artículo discute la estimación de variables continuas (leyes) utilizando el modelado implícito.
Uno de los motores subyacentes del modelado implícito para producir esta descripción de función matemática es la función de base radial (RBF). En esencia, la RBF es una suma ponderada de funciones posicionadas en cada punto de datos. Se resuelve un sistema de ecuaciones lineales para derivar los pesos y los coeficientes de cualquier modelo de deriva subyacente. Una vez derivada, la RBF se puede resolver para cualquier punto no muestreado o promediarse sobre cualquier volumen para proporcionar una estimación de grado. Es posible, por ejemplo, consultar la RBF en una rejilla regular para obtener una estimación de los grados de bloque. Dada la facilidad de creación de una RBF y su capacidad para predecir el grado, surge la pregunta de cómo se comparan los grados derivados de la solución de una RBF con las estimaciones de grado derivadas de métodos convencionales de interpolación geoestadística (por ejemplo, kriging ordinario (OK)).
El propósito de este artículo es describir en términos sencillos:
• la estructura básica de una RBF
• el papel de la elección paramétrica en la solución de las RBF y cómo esto influye en el carácter de la solución
• las similitudes y diferencias fundamentales entre las RBF y los estimadores geoestadísticos convencionales.
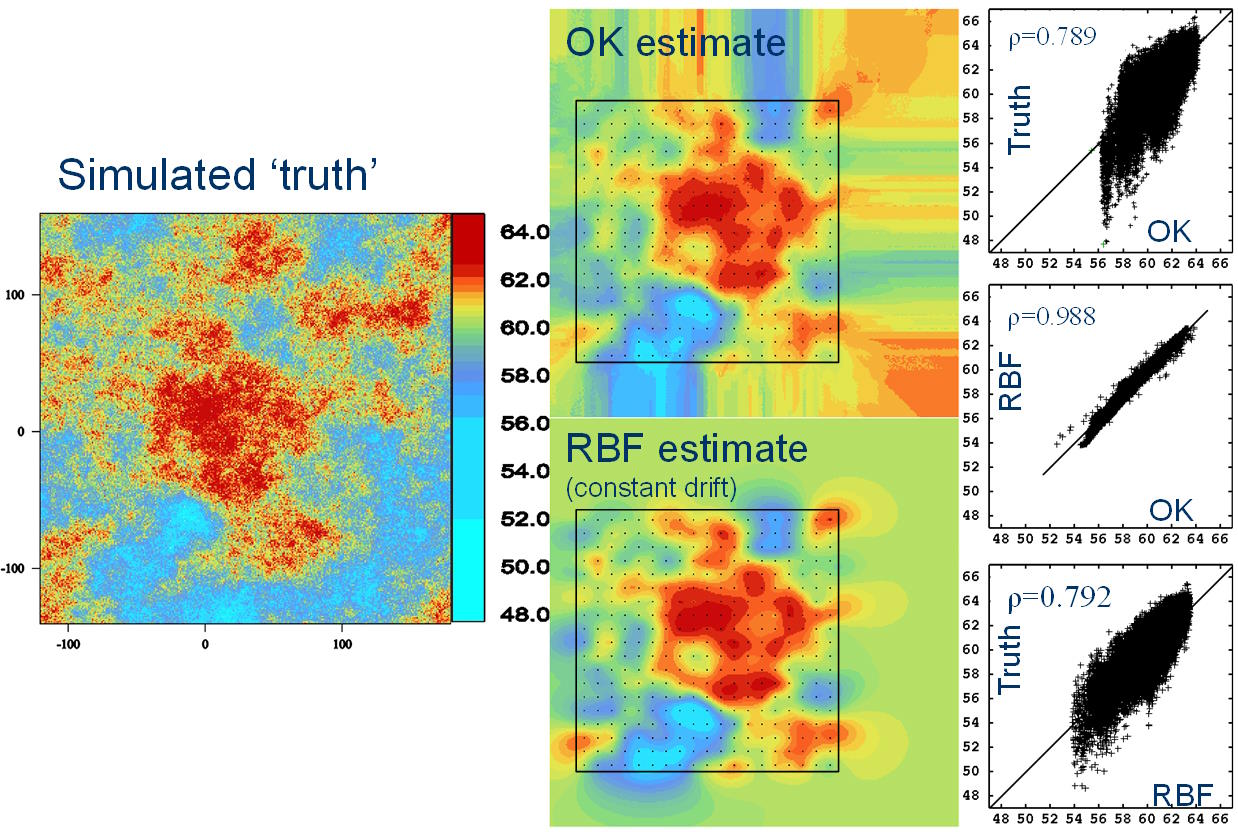
Utilizando una simulación condicional de alta resolución, se muestra que en muchas situaciones, las estimaciones de la RBF y el OK son muy similares.
INTRODUCCIÓN
En los últimos años, los modelos alámbricos implícitos se han utilizado cada vez más para desarrollar formas 3D coherentes para su uso posterior en la estimación a través de métodos tradicionales (por ejemplo, kriging ordinario (OK)). Cowan et al (2003) introdujeron el término «modelado implícito» en la tarea de modelar geometrías de superficies geológicas. El modelado implícito describe un enfoque del modelado espacial en el que una combinación de datos y controles paramétricos especificados por el usuario definen una función de volumen matemática única. Este enfoque puede aplicarse al modelado de superficies a partir de variables categóricas, como la litología, o al modelado de variables continuas, como leyes geoquímicas en todo el espacio. La función más común actualmente en uso para el modelado implícito es la función de base radial (RBF). El término implícito se usa porque la superficie que se modela existe implícitamente dentro de la función de volumen como una superficie isopotencial definida por los datos en lugar de por un proceso de dibujo explícito. Esta función de volumen puede luego ser cuadriculada, o ‘renderizada’, en una estructura alámbrica para su visualización o posterior uso de modelado.
El método de modelado implícito ahora se usa ampliamente para el modelado de la geometría de la superficie a partir de datos de registro categóricos y para el modelado de «isosuperficies de grado» basadas en variables de grado continuo. Lo que muchas personas desconocen es que los modelos implícitos utilizados para generar «isosuperficies de ley» también pueden proporcionar estimaciones puntuales o de bloque de la ley. En muchas situaciones, son muy similares a las estimaciones obtenidas con métodos de estimación más familiares, como OK. Hay una razón para esto: se puede demostrar (Carr et al, 2001; Chiles y Delfiner, 1999; Costa, Pronzato y Thierry, 1999) que el RBF es matemáticamente equivalente a una formulación particular de kriging (kriging dual (DK) ). En la práctica, las estimaciones derivadas de los RBF también suelen ser muy similares a las producidas por OK.
El propósito de este documento es describir (en términos simples) la estructura básica de un RBF e ilustrar las similitudes que tiene con el kriging. También discutiremos brevemente el papel de la elección de parámetros en la solución de RBF y mostraremos cómo esto influye en el carácter de la solución.
LA IDEA DE LA INTERPOLACIÓN
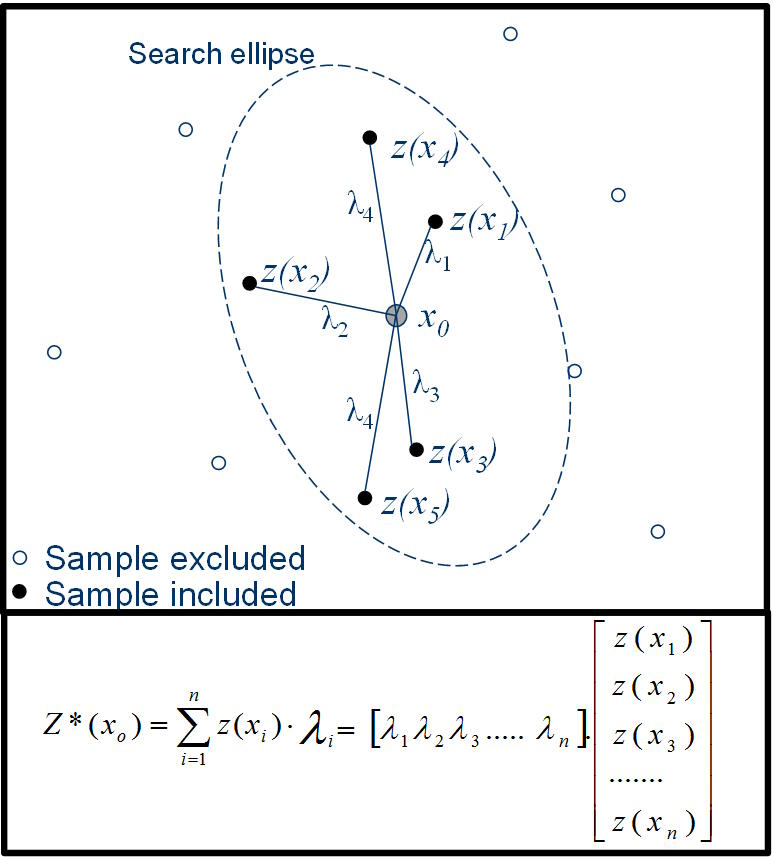
La interpolación es el proceso de predecir (estimar) el valor de un atributo en una ubicación no muestreada a partir de mediciones del atributo realizadas en los sitios circundantes (Figura 1). En la interpolación lineal, la calificación en la ubicación objetivo se calcula como un promedio lineal ponderado de los datos de la muestra. Diferentes interpoladores usan diferentes métodos para determinar el valor de los pesos. Cuando el punto a estimar está dentro del campo de datos disponibles, el proceso se denomina interpolación; cuando el punto está fuera del campo de datos, el proceso se denomina extrapolación. Este proceso puede realizarse en una, dos, tres o cuatro dimensiones. Por lo general, en la estimación de recursos minerales, nos preocupamos por problemas prácticos tridimensionales: predecir la ley de un atributo (por ejemplo, una ley de metal) en ubicaciones no muestreadas a partir de valores medidos en muestras de perforación dispersas. Es una suposición subyacente que el atributo que intentamos predecir es espacialmente continuo, que toma un valor real en todas las ubicaciones posibles. Hay muchas formas diferentes de interpolador posibles. El más básico es el método constante por partes, más conocido como estimación del vecino más cercano, en el que cualquier ubicación no muestreada simplemente toma el valor del punto de datos más cercano. El estimador continuo resultante toma la forma de un patrón de mosaico, con parches de ley constante separados por pasos repentinos. Esta no es una representación muy realista de la forma en que se observa que los atributos reales, como las leyes del metal, varían en la práctica, y otorga pesos significativamente diferentes a las muestras en los extremos espaciales del conjunto de datos. En aras de la simplicidad en la discusión, este documento considerará que el atributo que se predice es el grado de un metal, sin embargo, la idea puede extenderse simplemente a cualquier variable continua.
El interpolador kriging (local)
Los interpoladores se dividen en dos tipos generales: globales o locales. Un interpolador global tiene en cuenta todos los puntos conocidos para estimar un valor, mientras que la interpolación local utiliza un subconjunto de datos, generalmente definido por una vecindad de búsqueda centrada en el punto que se estima.
El interpolador que probablemente se usa más comúnmente en minería es kriging, o más particularmente OK. La idea general es sencilla: la estimación de un punto se basa en una combinación lineal ponderada de valores de datos locales, y los pesos se calculan de tal manera que se minimiza la varianza del error en función de un modelo asumido para la covarianza espacial. Kriging se basa en una serie de suposiciones clave:
La suposición subyacente es que las observaciones de la muestra se interpretan como los resultados de un proceso aleatorio. La variable en estudio (por ejemplo, grado de Fe
s) se puede describir mediante una función aleatoria matemática. Esta conceptualización de los datos es simplemente un ingenioso truco que nos permite describir la realidad como el resultado de un modelo probabilístico.
El paso clave en el modelado geoestadístico es la adopción de un modelo espacial (el variograma) que describe la función aleatoria subyacente. La elección del modelo espacial normalmente se basa en ajustar una función a los datos experimentales disponibles, aunque no existe un vínculo explícito y esta función a menudo se elige más por conveniencia matemática que por derivarse de un análisis del proceso de mineralización.
La adopción de un modelo que resume el proceso aleatorio permite que la varianza del error (la varianza de la diferencia «en promedio» entre la calificación estimada y la verdadera) se exprese en términos de covarianzas espaciales y factores de ponderación aplicados a las muestras (pesos kriging). Las covarianzas espaciales se especifican mediante la elección del modelo de variograma realizado y las ubicaciones de los datos. El álgebra convencional proporciona los medios para encontrar el conjunto de pesos de kriging que minimiza la varianza del error.
Estos atributos son característicos de todos los sistemas kriging. Las variantes más comunes de kriging son kriging simple (SK), OK y kriging universal (UK). Lo que los distingue es la forma en que la variación en la ley media (deriva) se incorpora a los sistemas kriging.
Diferentes sistemas de kriging
Como se explicó anteriormente, lo que distingue a los diferentes sistemas de kriging es la forma en que se incorpora la variación en la ley media (deriva) en los sistemas de kriging.
kriging simple
SK asume que la expectativa de la media (m) es constante en todo el dominio y de valor conocido (estacionariedad intrínseca). Esto equivale a decir que la componente de deriva es constante y conocida. Por lo general, se estima utilizando la media desagregada de los datos muestrales disponibles.
El estimador SK en cualquier punto se reduce a una combinación de dos componentes: un promedio ponderado de los datos locales y la media del dominio. Las estimaciones cercanas a los datos darán más peso a la estimación local, mientras que las estimaciones más alejadas de los datos estarán dominadas por la media del dominio.
SK rara vez se usa en la práctica ya que la suposición subyacente (constante, media conocida) es demasiado severa para la mayoría de las aplicaciones. Además, la incorporación de la nota media como término ponderado en la estimación SK hace que, lejos de la influencia
de datos de la muestra, el estimador vuelve a la nota media. En la mayoría de los depósitos minerales, la ley disminuye hacia el margen y, a menudo, aquí es donde los datos de perforación son más bajos. Tener un estimador que revierte hacia la media en esta región generalmente no es realista.
kriging ordinario
La suposición que distingue a OK de otros sistemas de kriging es que la expectativa de la media es desconocida pero es constante a la escala de la vecindad de búsqueda (una suposición conocida como cuasiestacionariedad dentro de la hipótesis intrínseca). Lo que esto significa en la práctica es que no debería haber tendencias presentes en la calificación media local por debajo de la escala de la búsqueda. Este es un concepto algo resbaladizo ya que es inusual tener una escala clara en la que se aplica esta separación. En la práctica, esto significa que las variaciones en las calificaciones muestreadas presentes dentro de un vecindario local deben ser fluctuaciones aleatorias plausibles en torno a una calificación media local constante, sin que se presente una fuerte tendencia. Esto permite que el sistema OK se adapte a la variación en la media local de modo que la estimación siempre se centre en el promedio ponderado de las muestras presentes en el vecindario local. Esto significa que la especificación de la vecindad de búsqueda local tiene una influencia crítica en la calidad del estimador kriging; en particular, la vecindad debe ser lo suficientemente grande para que los datos contenidos representen adecuadamente la ley media local.
Al extrapolar más allá de los límites de los datos, el estimador OK no revierte hacia la media global, sino que mantiene la media local especificada por las muestras más cercanas.
kriging universal
La teoría de UK fue propuesta por Matheron en 1969 (Armstrong, 1984) para proporcionar una solución general a la estimación lineal en presencia de deriva. Esta teoría asume que la media local es desconocida pero varía de manera sistemática y puede escribirse como una expansión finita de funciones de base conocidas (f) y coeficientes fijos (pero desconocidos) (a). La información de deriva puede entonces incorporarse en la expresión de la varianza de la estimación.
Rápidamente se dio cuenta de que existen graves dificultades prácticas en la implementación del Reino Unido. El desarrollo del sistema del Reino Unido supone que se conoce el variograma subyacente (que incorpora la deriva); en esta situación, el sistema kriging arroja correctamente tanto los coeficientes de deriva como los pesos. En la práctica, sin embargo, el variograma subyacente siempre se desconoce. Esto nos deja con un problema circular; para calcular los residuos necesitamos conocer la deriva,
pero para conocer la deriva necesitamos conocer el sistema del Reino Unido. Esta circularidad no excluye el uso de UK, pero sí significa que se debe tener mucha cautela en su aplicación. Asumir un modelo de deriva y trabajar solo con residuos dará como resultado una estimación sesgada del verdadero variograma subyacente (Armstrong, 1984).
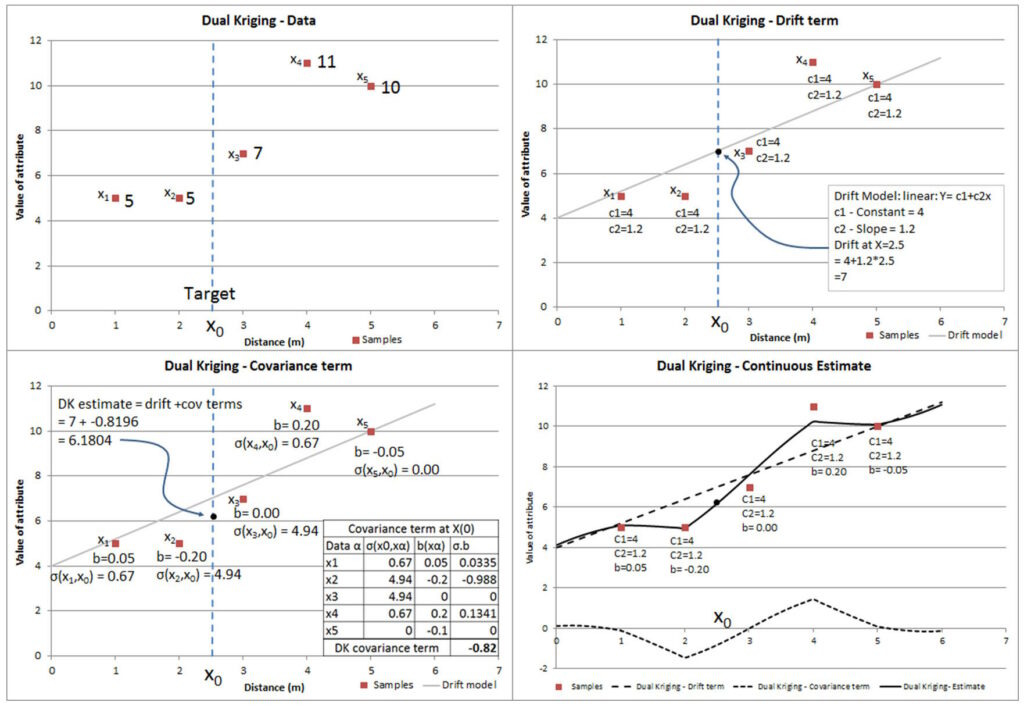
Doble kriging
Los estimadores de kriging discutidos anteriormente se basan en combinaciones lineales de valores de datos de muestra. También es posible reescribir el estimador UK en términos de covarianzas σ(xi,x) y funciones de deriva f l(x) únicamente, omitiendo cualquier referencia directa a los datos. Esto se conoce como DK. El desarrollo no se muestra aquí, pero se da una exposición clara en Chiles y Delfiner (1999) y Galli, Murillo y Thomann (1984). El término ‘dual’ se origina de una derivación alternativa de estas ecuaciones por minimización en un espacio funcional, similar a splines (Chiles y Delfiner, 1999).
Expresado en inglés, la estimación en cualquier punto (x0) es la suma de dos componentes:
Un componente determinista transportado por la suma de los términos de la función de deriva en la ubicación objetivo: c f (x)
Un componente probabilístico calculado como la suma ponderada de las covarianzas entre la ubicación objetivo y todas las ubicaciones de muestra: b v(x ,x)
la función de covarianza (o variograma) es mayor en distancias cortas, es fácil ver que este término será mayor cuando el punto objetivo esté cerca de los datos. Los valores del coeficiente b están influenciados por el agrupamiento y la distancia del valor de la muestra de la ley media local estimada por el modelo de deriva.
La naturaleza de la función de deriva es una elección impuesta por el usuario, y la función de covarianza (o variograma en el caso intrínseco) es igualmente una elección especificada por el usuario. Luego, los valores de los coeficientes b y c se calculan de la misma manera que para otros sistemas de kriging, imponiendo restricciones en el sistema que permiten obtener una solución única (ver Chiles y Delfiner (1999) para más detalles).
Este sistema no es fácil de visualizar. La Figura 3 muestra cómo el estimador DK se compone de deriva y componentes probabilísticos, y que ninguno hace referencia directa a los valores muestreados. Tenga en cuenta que, si bien la estimación de deriva (y los coeficientes) y la estimación probabilística (y los coeficientes) se muestran por separado, en realidad se derivan simultáneamente. La deriva afecta la estimación en todo el espacio, mientras que los coeficientes probabilísticos describen la influencia local alrededor de cada punto de datos.
Una de las principales ventajas del sistema DK es que los coeficientes de deriva y covarianza solo necesitan resolverse una vez y luego pueden usarse para hacer una estimación en cualquier ubicación.
El principal inconveniente del método es que el uso de una vecindad global da como resultado un sistema muy grande de ecuaciones simultáneas, con una ecuación por muestra y una para cada función de deriva.
Funciones de base radial
El RBF es una familia de técnicas matemáticas que se ha aplicado a muchos problemas de interpolación espacial y es la base de la mayoría de los algoritmos de «modelado implícito» que se utilizan en la actualidad. Se basa en una premisa de partida algo diferente a la teoría de las variables regionalizadas en la que se basa el kriging: en lugar de considerar que la variable objetivo es una realización de una función aleatoria con una estructura definida, el RBF se basa en la interpolación de una función predefinida de criterios matemáticos como la minimización de la curvatura. En la práctica, esta diferencia es solo semántica, porque el kriging tradicional también usa determinadas funciones, excepto que estas se ajustan a los datos experimentales y se han elegido para adaptarse al modelado de los datos. Matemáticamente, existe una equivalencia entre DK y el modelado con RBF, y también es posible elegir la función RBF ajustando los datos experimentales. De hecho, debido a que los variogramas como el esférico son definidos positivos (Chiles y Delfiner, 1999, p. 59), son adecuados para usarse como RBF.
El interpolante para un RBF tiene una forma muy similar a la expresión general de kriging: la variable objetivo es se considera que está compuesto por un término de deriva y un término que es un promedio ponderado de los valores de función que dependen de las ubicaciones de los datos.
El término de la derecha se refiere al conjunto de K funciones de deriva (qk(x)), cada una de las cuales tiene un coeficiente (ck) aplicado globalmente a todos los datos.
De la misma manera que para DK, se imponen condiciones que hacen que el sistema sea solucionable. En este caso, las condiciones son que: el producto de los coeficientes RBF y los coeficientes de la función de deriva en cada punto de datos debe sumar cero en todos los puntos de datos, y la función debe devolver el valor de los datos en un punto de datos (ver Cowan et al. (2001) para detalles y Chiles y Delfiner (1999) para el ejemplo paralelo de DK). Estas condiciones permiten expresar el sistema como un conjunto de ecuaciones lineales. Esto se muestra en forma de matriz de la siguiente manera:
Accede al articulo completo en nuestra biblioteca Digital.
Escala es un término usado frecuentemente en fotogrametría para definir los elementos y características que pueden presentarse sobre un mapa; este mapa es generado a partir de imágenes que deben tener la misma escala o superior a la que se requiere trabajar. Es decir, no es posible generar mapas a una escala de 1:2,000 si nuestras imágenes de manera visual están a una escala de 1:10,000. En el ejemplo anterior, para poder generar un plano a escala 1: 2,000 necesariamente nuestra imagen fuente debe tener una escala igual o menor.
Regla para determinar la mejor escala para trabajar usando imagenes Satelitales
La siguiente tabla es un extracto mostrado en ESRI Mapping Center. El cual indica que para determinar la mejor escala de un plano en función de la resolución espacial de una imagen se debe aplicar la siguiente relación:
Escala del mapa = Resolución de imagen (en metros) * 2 * 1000
ESCALA DE MAPA
RESOLUCIÓN ESPACIAL (metros)
1:1,000
0.5
1:5,000
2.5
1:10,000
2.0
1:50,000
25.0
ESRI Mapping Center
Ejemplo.
Usando las imagenes obtenidas con el software SAS Planet podemos realizar los siguientes Ejemplos.
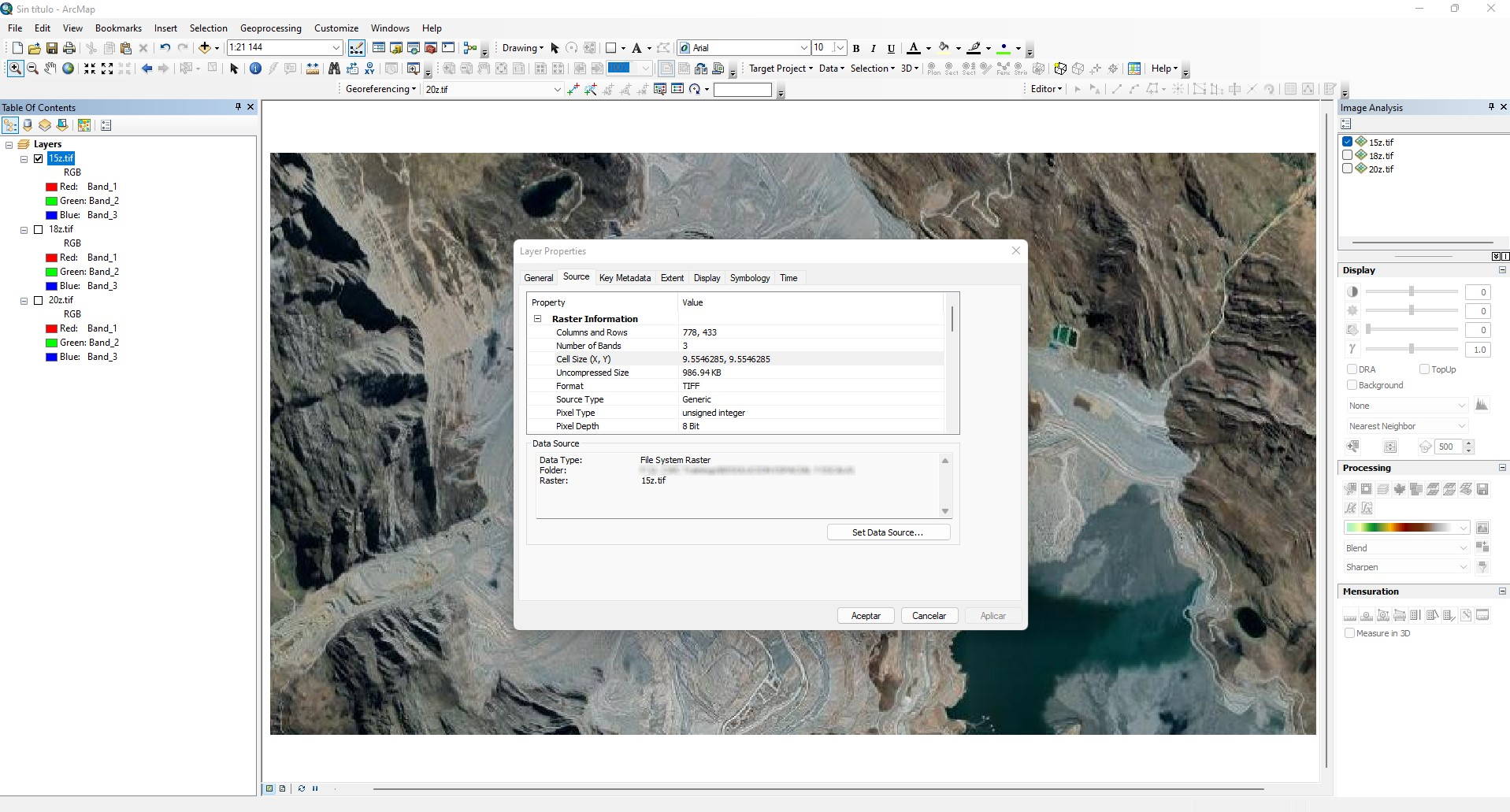
Zoom 15z
La resolución espacial de la imagen con Zoom 16z es: 9.55 m
Aplicando la fórmula:
Escala del mapa = Resolución de imagen (en metros) * 2 * 1000
Escala del mapa = 9.55*2*1000
Escala del mapa = 19,100
La mejor escala de mapa para trabajar es: 1:20,000
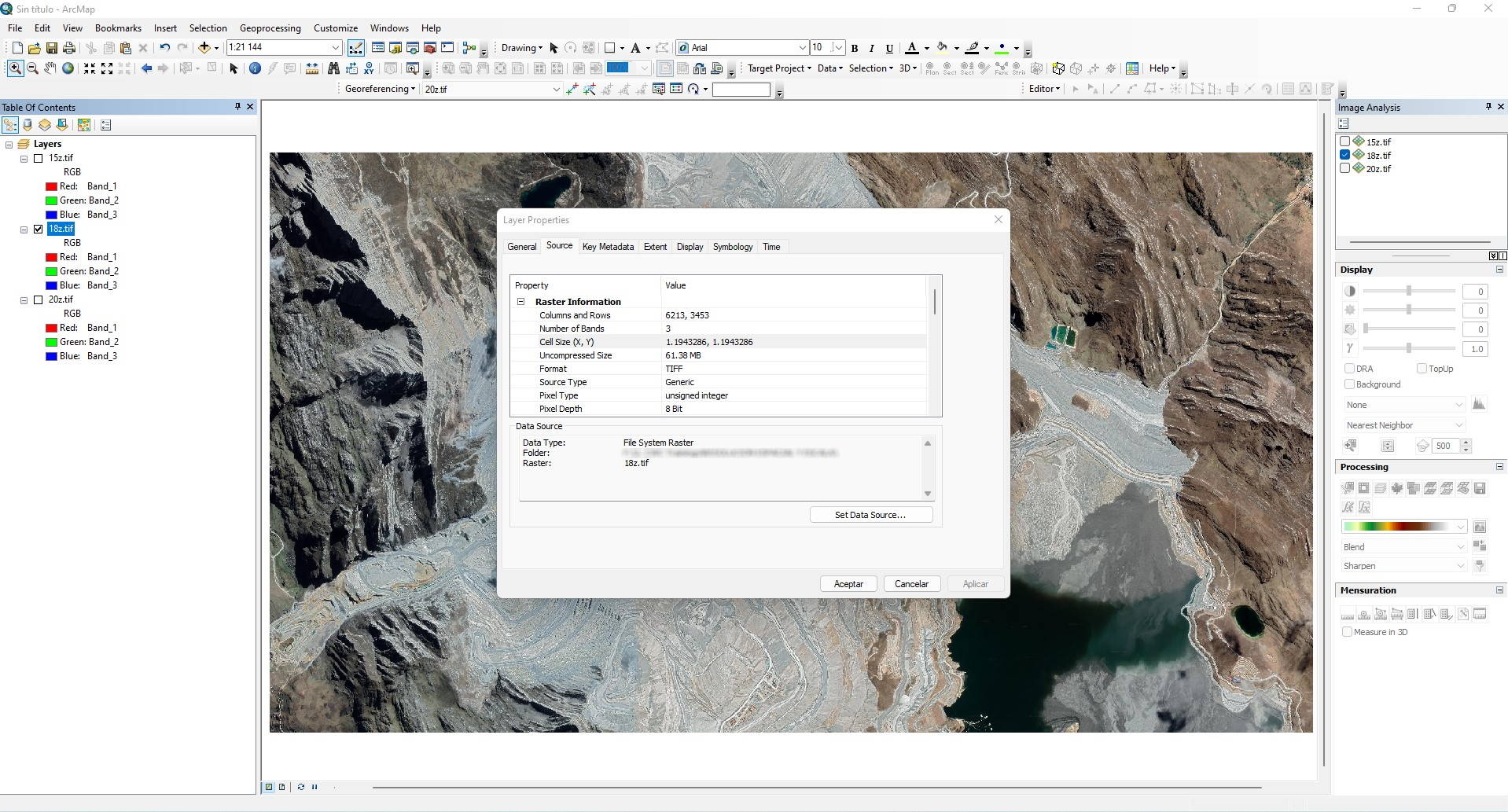
Zoom 18z
La resolución espacial de la imagen con Zoom 18z es: 1.19 m
Aplicando la fórmula:
Escala del mapa = Resolución de imagen (en metros) * 2 * 1000
Escala del mapa = 1.19*2*1000
Escala del mapa = 2380
La mejor escala de mapa para trabajar es: 1:2,500
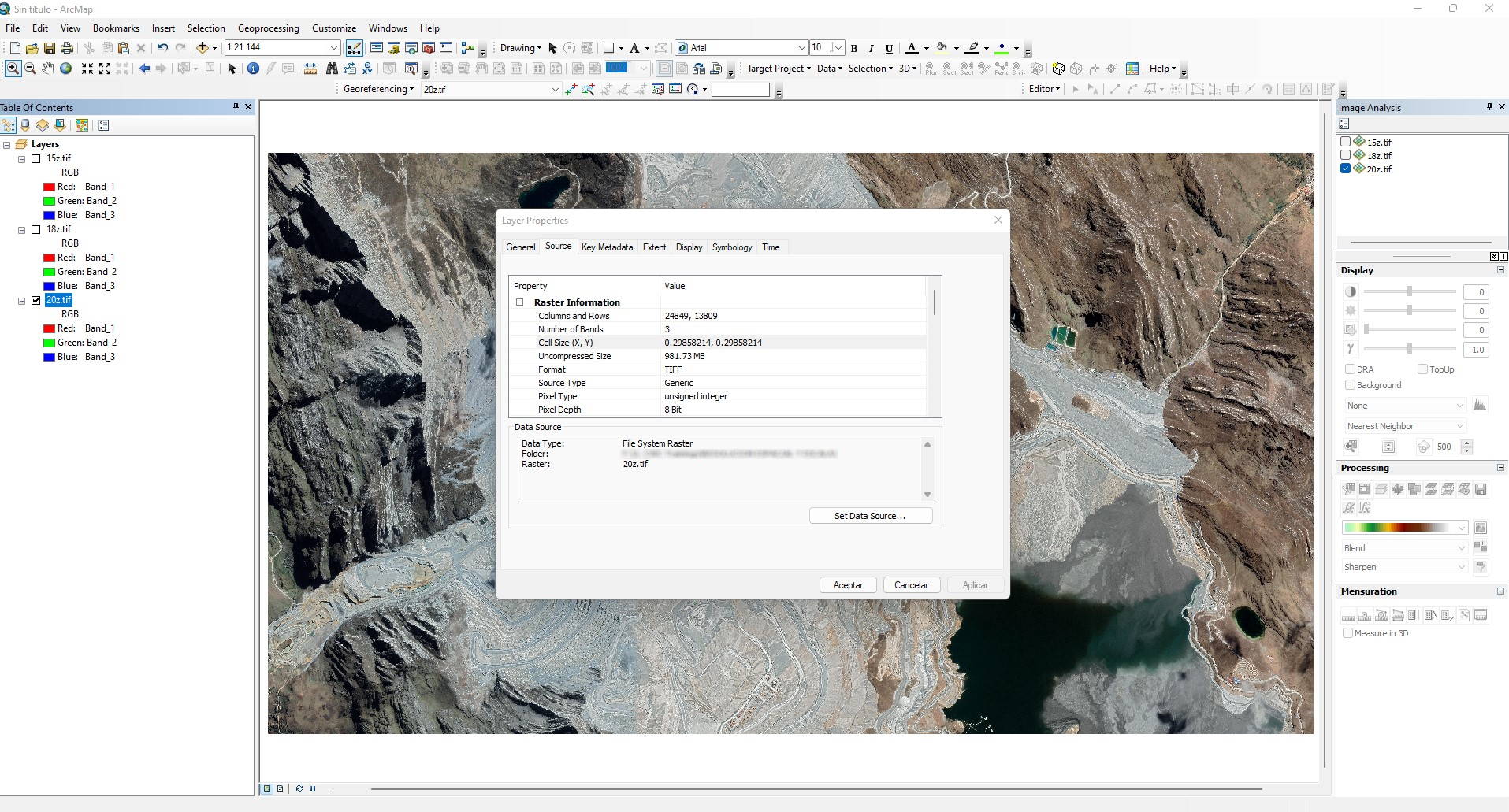
Zoom 20z
La resolución espacial de la imagen con Zoom 20z es: 0.29m
Aplicando la fórmula:
Escala del mapa = Resolución de imagen (en metros) * 2 * 1000
En Muchas ocasiones se nos es difícil definir los conceptos de asociaciones mineralógicas, este es un video donde se explica de manera simple y clara la importancia y las diferencias de cada uno de los tipos de asociaciones mineralógicas en la estabilidad geoquímica.
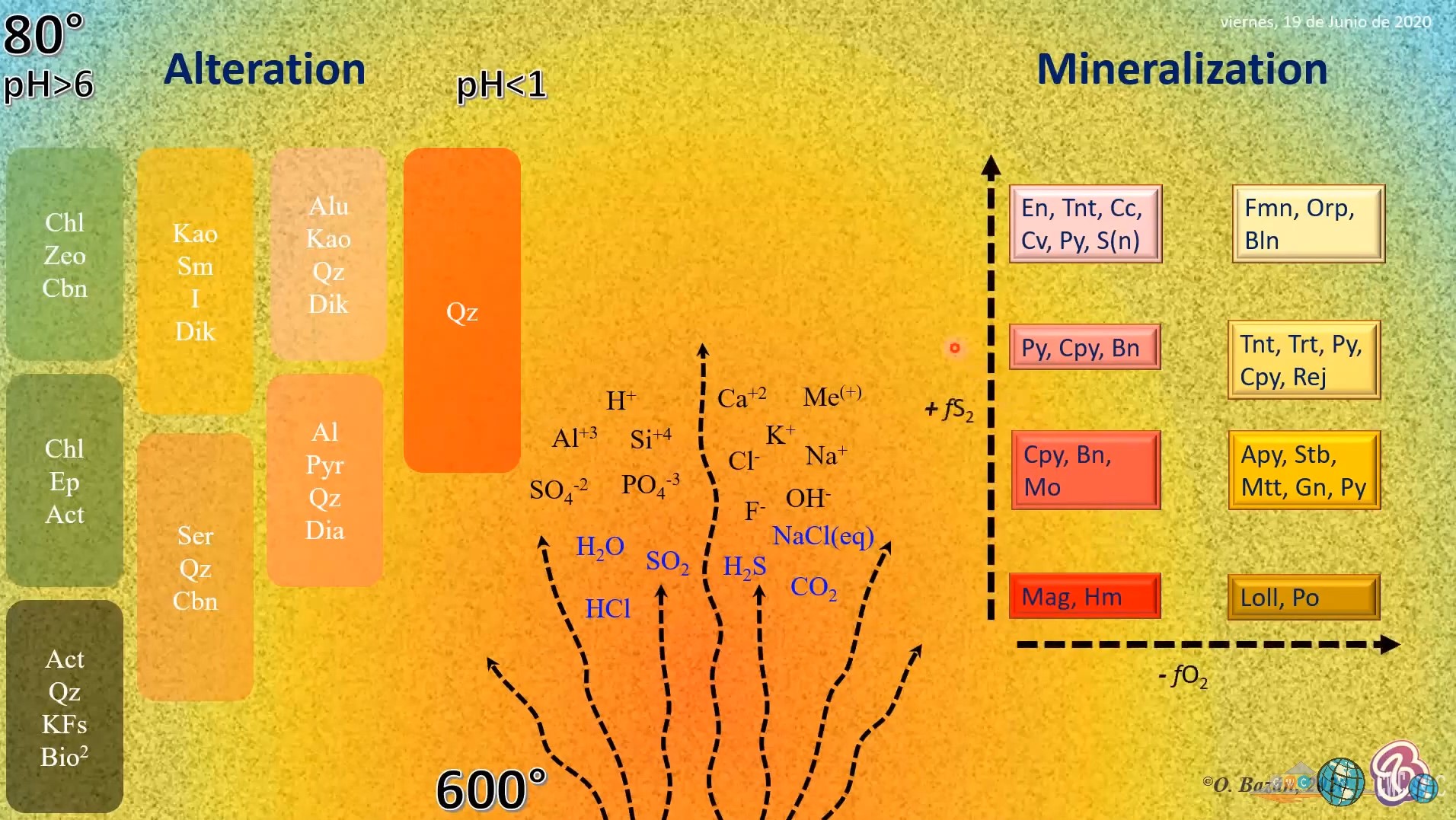
Estabilidad Geoquímica de asociaciones mineralógicas – Definiciones
Asociación:
Grupo de minerales que ocurren juntos pero que no están necesariamente en contacto ni necesariamente depositados al mismo tiempo, y no implica condiciones de equilibrio. Van separados por comas
Ensamble:
Grupo de minerales que se encuentran en contacto directo y no muestran evidencia de reacción entre ellos, implica un equilibrio químico. Van separados por el signo + o –
Paragénesis:
Asociación mineral característica que connota la formación contemporánea y/o relación temporal de los minerales. No necesariamente implica condiciones de equilibrio.
Zonación:
Relación espacial de una asociación de minerales y/o ensambles mineralógicos, puede connotar condiciones de equilibrio químico o superposición de múltiples eventos a través del tiempo.
Este video es parte del curso de: Procesos de alteración y mineralización en sistemas magmático-hidrotermales⭐⭐⭐
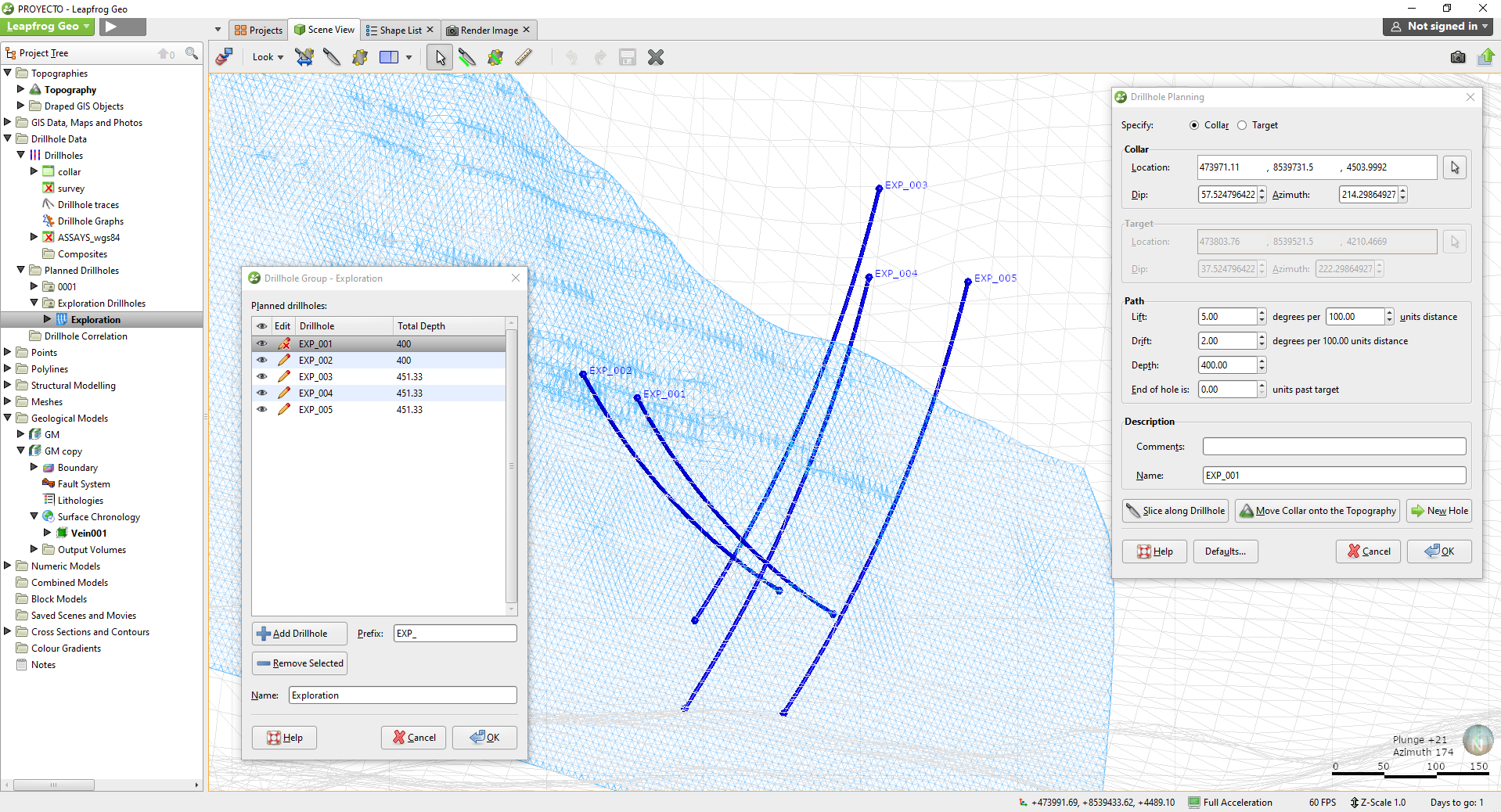
Uno de los principales costos de un proyecto de exploración es el programa de perforación. La planificación de perforaciones en 3D basada en el conocimiento existente es una manera fácil de maximizar el valor de cualquier perforación futura y se puede lograr rápida y fácilmente en Leapfrog Geo . En este tutorial aprenderemos a través de los pasos necesarios para planificar una campaña de perforación en Leapfrog Geo, luego configurará un archivo de escena para que el equipo de campo pueda ver hacia dónde debe ir cada perforación, así como qué litología y grado se espera que intercepte.
El primer paso es definir el área de su proyecto; un buen comienzo es importar los datos existentes. Esto podría incluir una superficie topográfica, cualquier perforación existente, una fotografía aérea o un mapa geológico y datos GIS como lagos, ríos, caminos de acceso y límites de viviendas.
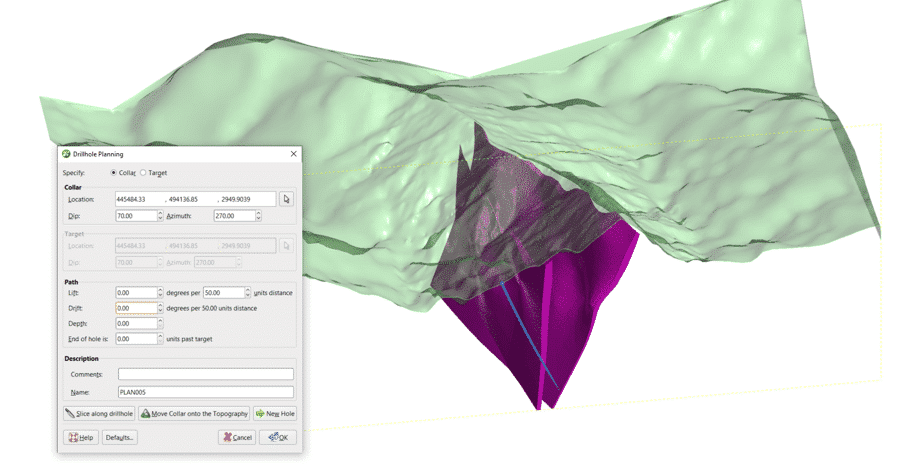
Una vez que haya importado los datos existentes, podrá comenzar a visualizar en 3D dónde es una ubicación adecuada para colocar su collar. Si ha creado algún modelo geológico o de ley, también puede visualizar dónde está su objetivo potencial.
Para crear una perforación planificada, haga clic con el botón derecho en la carpeta ‘Perforaciones planificadas’ y haga clic en ‘Planificar perforación’.
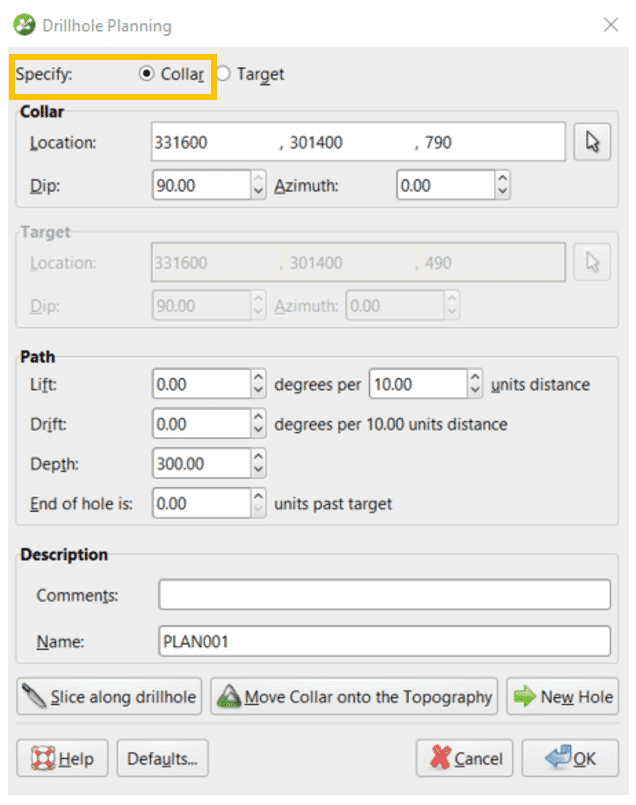
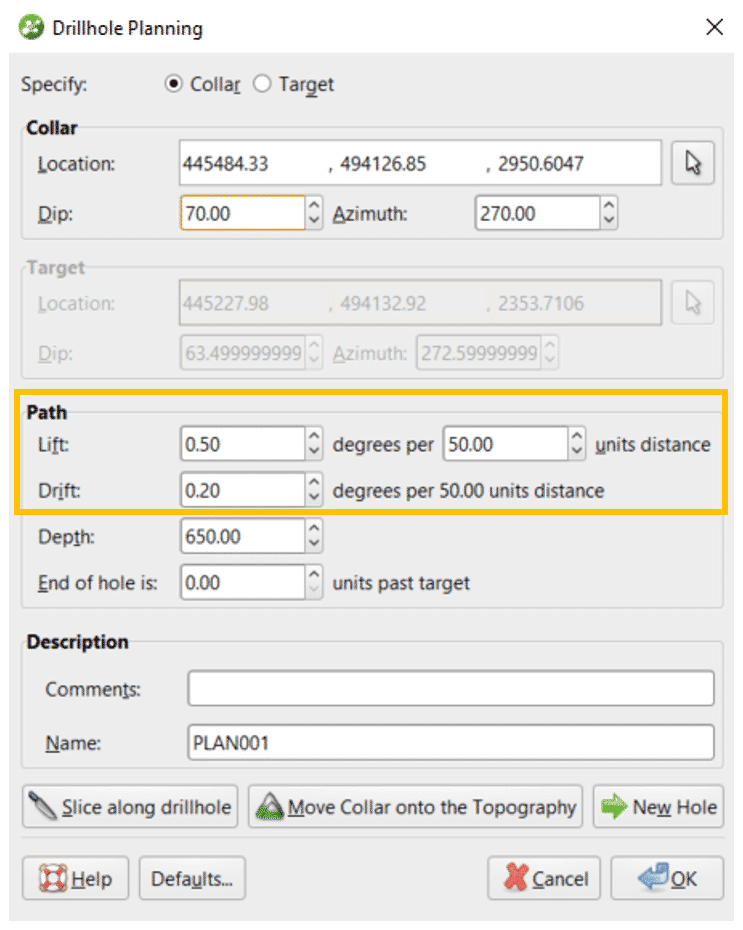
Hay dos opciones que puede elegir; puede especificar una ubicación de collar o una ubicación de destino. Especificaremos la ubicación del collar, ya que es más común tener un punto conocido en la topografía para colocar su collar.
Asegúrese de que la opción ‘Collar’ esté seleccionada en la parte superior de la ventana. Arrastre su topografía a la escena, así como un modelo geológico o de grado existente, si tiene uno.
Gire la escena para que pueda ver la ubicación del collar, así como el punto que le gustaría cruzar.
Haga clic en el icono del cursor en la ventana Planificación de perforaciones.
Haga clic en la ubicación de su topografía en la que le gustaría colocar su collar y arrastre el cursor a la ubicación de destino.
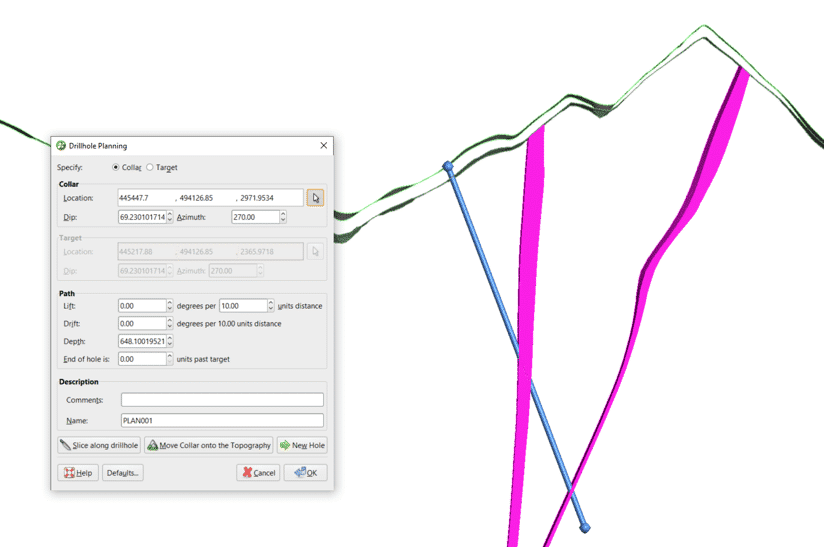
La ubicación, el buzamiento, el azimut y la profundidad, así como un nombre para el sondeo basado en la perforación actual, llenarán los campos en la ventana Planificación del sondeo.
El último paso es especificar una elevación y desviacion adecuadas para su sondaje; estos se pueden ingresar manualmente según la tendencia de los sondajes anteriores. Cuando cambie la elevación y la desviación, verá que cambia la ubicación de su objetivo. Puede cambiar manualmente el buzamiento y el azimut en la superficie para asegurarse de que su sondaje intercepte la ubicación deseada.
Haga clic en Aceptar
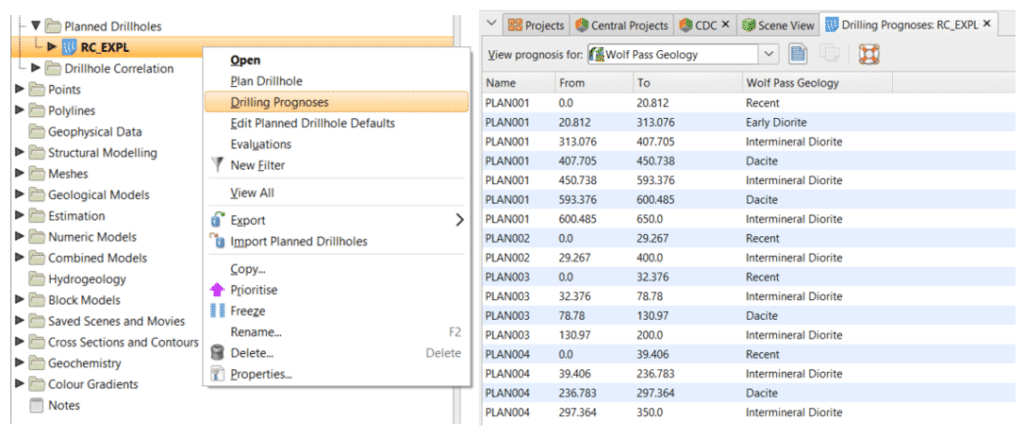
Drilling Prognoses (si ya tiene un modelo geológico previo)
Una vez que haya planificado su sondaje, haga clic con el botón derecho en el árbol del proyecto y seleccione ‘Drilling Prognosis’ para ver la litología esperada o la ley de fondo de pozo según el modelo actual de Leapfrog.
Puede establecer la elevación y la desviación por defecto haciendo clic derecho en la carpeta Planned Drillholes y seleccionando «Edit Plan Drillholes Defaults». En la ventana que aparece, puede especificar los valores predeterminados para la elevación y la desviación, así como otras opciones.
Uno de los valores predeterminados más útiles es la opción «Desplazamiento al siguiente sondaje», que le permite establecer la distancia y el acimut predeterminados para el siguiente sondaje. Esto puede resultar muy útil para planificar una cerca o una cuadrícula de perforaciones. En el siguiente ejemplo, la distancia predeterminada al siguiente pozo se ha establecido en 50 m, y también se ha establecido la dirección entre los sondajes, así como el buzamiento y el azimut de cada pozo. Una vez que se hayan creado estos ajustes predeterminados, haga clic en el botón «Siguiente agujero» para crear el siguiente sondaje planificado, luego repita hasta que se hayan planificado los agujeros deseados.
Exportación de un buzamiento y un azimut de ubicaciones
Una vez planificados los sondajes en 3D, se pueden exportar a un archivo csv para utilizarlos en el campo. La información exportada incluye todos los detalles del sondaje planificado.
Esto está escrito para aquellos que tienen problemas para modelar vetas con datos fragmentados, especialmente muestras de canales.
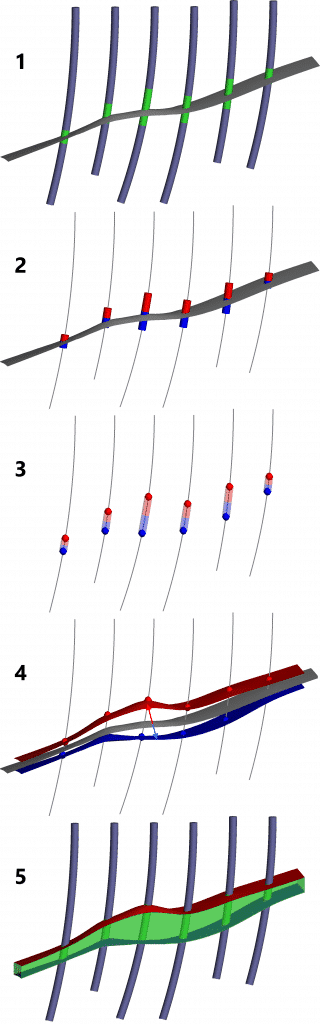
La herramienta de vetas de Leapfrog Geo fue diseñada para trabajar con datos de sondajes, idealmente perforaciones que intersecan ambas paredes de la estructura de veta tabular. Si está utilizando la herramienta de modelado de vetas con datos de muestra de canal fragmentados, encontrará útiles estos consejos y trucos. Cómo funciona la herramienta de vetas Para empezar, vale la pena comprender cómo funciona la herramienta de vetas. Consulte la figura 1 a continuación.
1. Primero, se genera una superficie de referencia a partir de los puntos medios de los intervalos de las vetas. 2. A los segmentos de veta se les asignan lados de pared colgante (HW) y pared de pie (FW) según su orientación a la superficie de referencia. 3. Se generan puntos HW y FW separados en los extremos de estos segmentos. 4. Se generan las superficies HW y FW; ambas son compensaciones de la superficie de referencia que se ajustan a los puntos respectivos. 5. El producto final es el volumen encerrado entre las superficies HW y FW.
Clasificación del segmento de veta
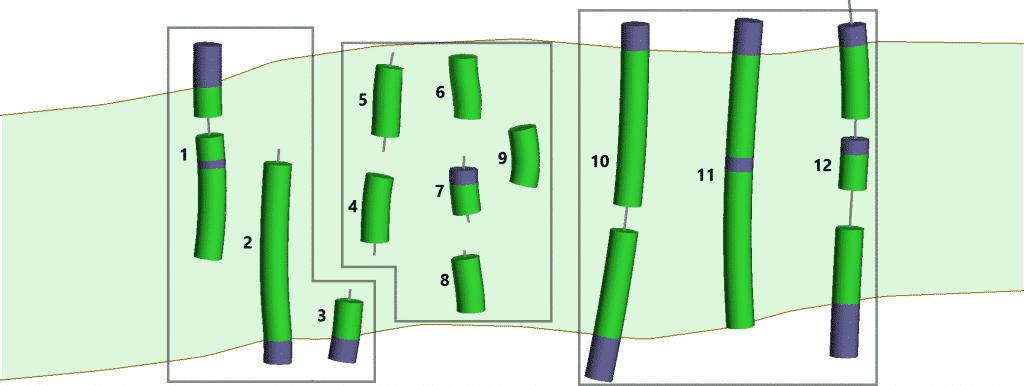
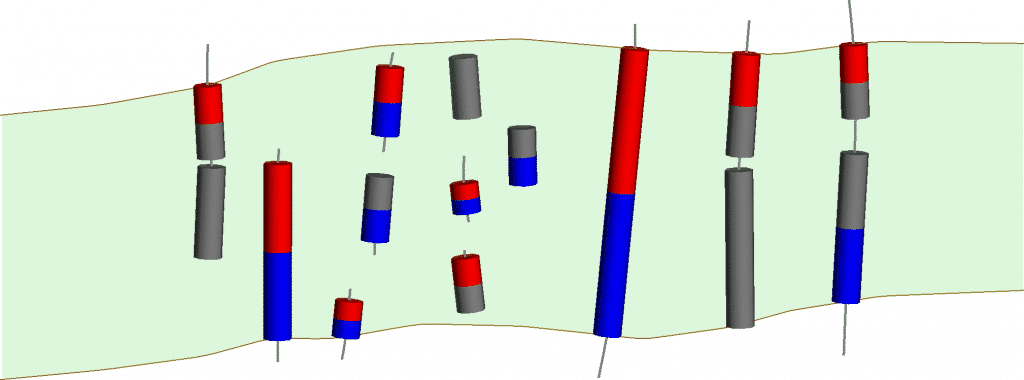
Debido a la forma en que Leapfrog Geo clasifica automáticamente los segmentos de vetas, podemos definir tres tipos básicos de muestras de vetas. • Las muestras de pared a pared están en el mismo agujero o canal y representan / tocan / intersecan ambas paredes de la verdadera estructura de la veta. • Las muestras de vetas incompletas son muestras que representan solo una pared de la verdadera estructura de la veta. • Las muestras de vetas internas no se cruzan con ninguna de las paredes verdaderas de la vena.
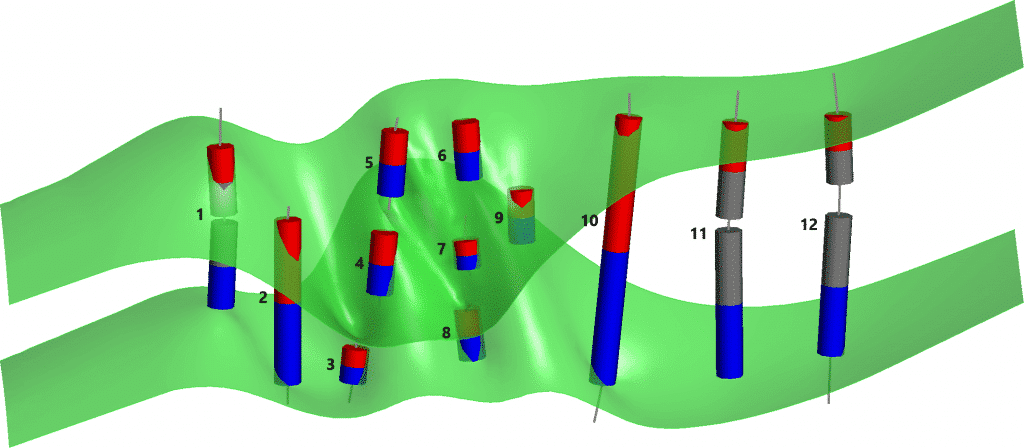
Figura 2. Grupos: Derecha = muestras de pared a pared, Izquierda = muestras incompletas, Centro = muestras internas
La estructura de la veta ‘verdadera’ está representada por el color verde claro, con las paredes representadas por las líneas marrones. Los intervalos verdes representan muestras de vetas registradas, los intervalos violetas representan muestras de «vetas externas» registradas, las líneas grises representan las secciones no muestreadas del pozo o canal.
Como puede ver en las figuras 3 y 4, la clasificación automática de segmentos de vetas de Leapfrog Geo hace un buen trabajo con tipos de muestras de pared a pared, incluso cuando están muy fragmentadas como el último hoyo, pero no funciona tan bien con los tipos de muestra incompletos y tipos de muestras internas. Estos tipos de muestras internas e incompletas pueden producir triangulaciones superficiales deficientes porque las superficies están en contacto con cada uno de sus respectivos puntos finales de segmento. Las superficies de la pared colgante y la pared del pie pueden cruzarse entre sí, generando agujeros en el volumen modelado de la veta.
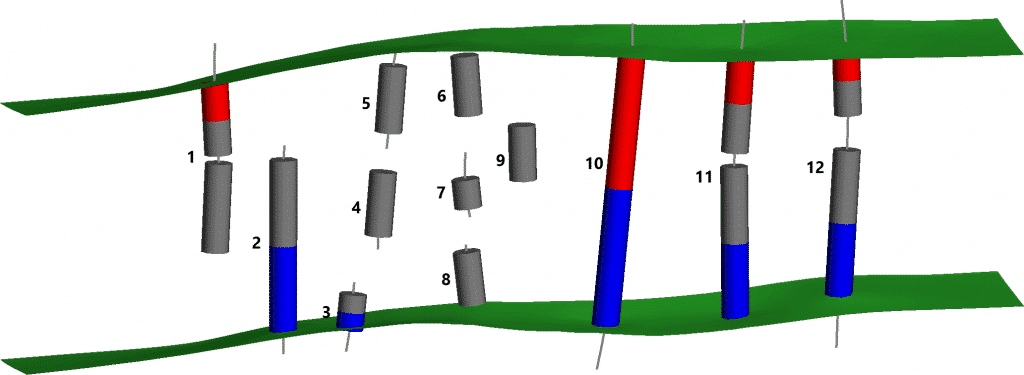
Figura 3. Resultados de la clasificación automática de segmentos de vetas de Leapfrog Geo. Cada extremo de segmento está representado por uno de estos tres tipos: Muro colgante (rojo), Muro de pie (azul) y Excluido (gris). Las triangulaciones de la superficie de la pared de la vena resultantes son verdes en esta imagen.
Figura 4. La clasificación ideal de estos segmentos de vetas. Todas las muestras internas se clasifican como «Excluidas». Se excluyen los extremos internos de los segmentos incompletos.
Edición manual
Con algunas ediciones manuales, puede lograr la clasificación de segmento de vena ideal en Leapfrog Geo.
Editar segmentos de vetas
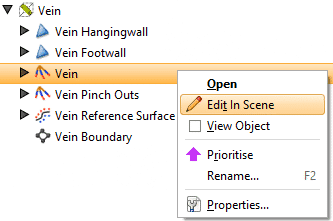
Para corregir los segmentos de vena en las muestras incompletas, deberá editar manualmente los segmentos de vena y anular sus clasificaciones automáticas. Haga clic con el botón derecho en los segmentos de la vena y seleccione Editar en escena (ver figura 5).
Figura 5. Para editar segmentos de vena, haga clic con el botón derecho en el objeto de segmentos de vena debajo de la vena en el árbol del proyecto.
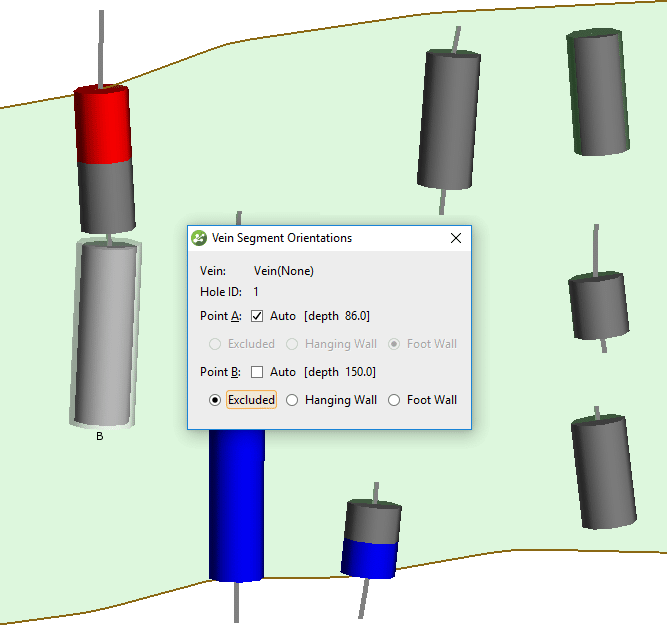
Haga clic en un segmento de vena, luego en el cuadro de diálogo Orientaciones de segmento de vena desmarque Auto para el punto (A o B) que es incorrecto. Fije el punto a la clasificación correcta. En el ejemplo ilustrado en la figura 6, el punto A del segmento parcial ha sido excluido por lo que será ignorado por las superficies de la pared de la veta. Repita esto para todos los segmentos de vena clasificados incorrectamente de muestras parciales.
Figura 6. Anule manualmente la clasificación de segmentos de vetas.
Ignorar muestras internas
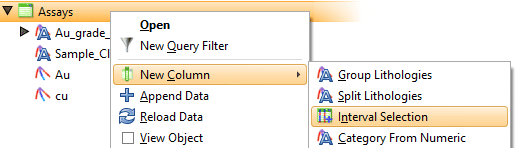
Puede llevar mucho tiempo anular manualmente la clasificación del segmento de vena, especialmente con muestras de vetas internas que deben tener ambos extremos de segmento (punto A y punto B) excluidos. Una forma de evitar esto es ignorar estas muestras con un filtro de consulta. Primero, deberá clasificar las muestras internas en la tabla de intervalos. Luego, cree una nueva selección de intervalo en la tabla de intervalos a partir de la cual se construyó su vena (consulte la figura 7).
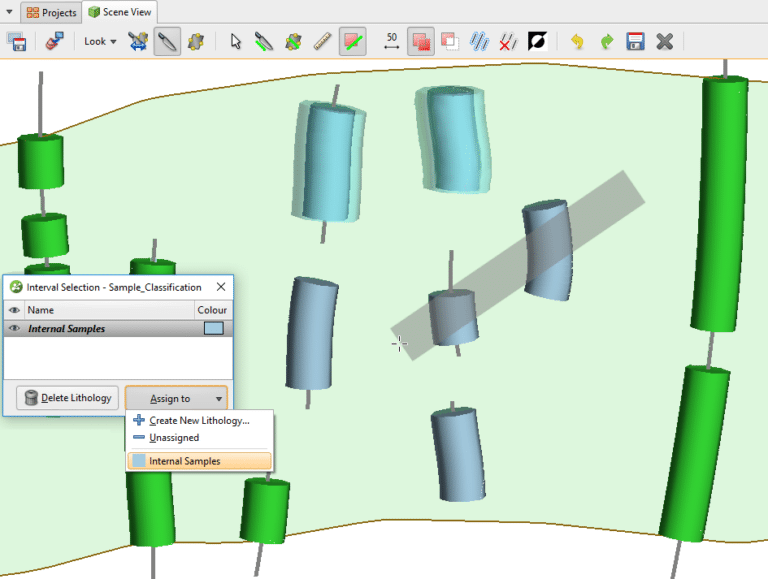
Seleccione y asigne todas las muestras internas a un nuevo código de ‘litología’ (ver figura 8)
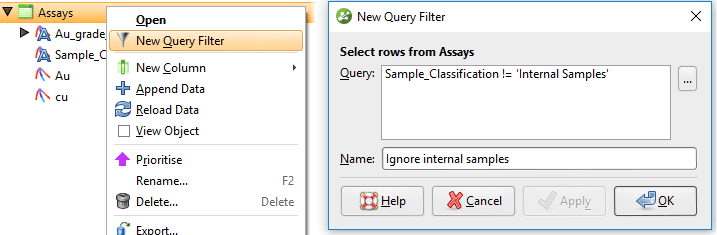
Una vez que se crea la columna de selección de intervalo, en la misma tabla de intervalo, cree un nuevo Filtro de consulta que ignore las muestras internas.
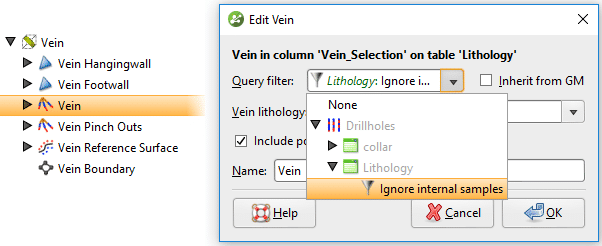
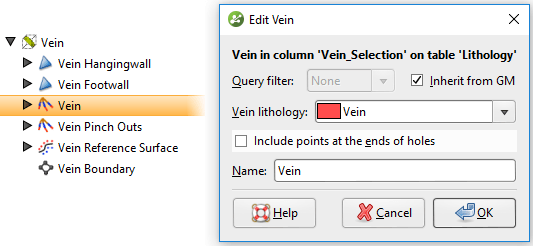
Figura 9. Cree un nuevo filtro de consulta que ignore las muestras de vetas internas. Para aplicar este filtro de consulta a la vena, abra los segmentos de la vena, desmarque la opción para heredar el filtro de consulta del GM (modelo geológico) y seleccione el nuevo filtro de consulta de la lista desplegable
Figura 10. Aplique un filtro de consulta a los segmentos de vena para ignorar las muestras internas.
Figura 11. Resultados de la clasificación de segmentos de vetas de Leapfrog Geo después de ignorar las muestras internas
Ignorar puntos al final de los agujeros
Dependiendo de los datos, es posible reducir el número de ediciones manuales excluyendo automáticamente los extremos del segmento al final de un agujero o canal. La configuración predeterminada para los segmentos de veta es incluir puntos al final de los agujeros. Para cambiar esta configuración, abra los segmentos de la vena haciendo doble clic (o haga clic con el botón derecho y seleccione Abrir), resaltados en naranja en la imagen, luego desmarque la opción para incluir puntos en los extremos de los agujeros (ver figura 12).
Figura 12. Desmarque la opción para incluir puntos en los extremos de los agujeros.
Figura 13. La clasificación automática de segmentos de veta que excluye puntos en los extremos de los pozos.
Como puede ver en la figura 13, los extremos de los segmentos de veta se excluyen al final de los orificios o canales. Esto ha resuelto el problema de clasificación de algunas de las muestras internas e incompletas. Sin embargo, si hay muchas muestras de vetas que se extienden hasta el final de los orificios (p. Ej., El orificio 11), o si la vena representa un caparazón de grado que debe encerrar firmemente todas las muestras de vetas, es posible que cambiar este ajuste no siempre sea apropiado
Conclusión
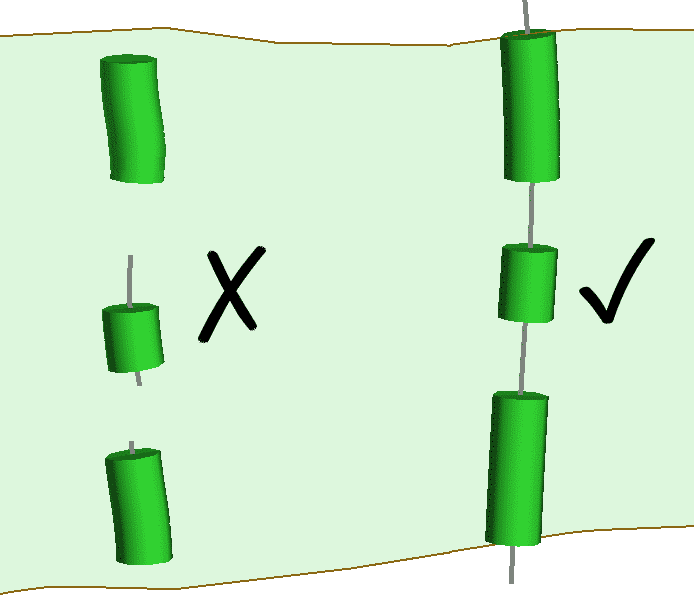
Con respecto a la clasificación automática de segmentos de vetas de Leapfrog Geo, el tipo de muestra de veta más recomendado para usar es de pared a pared. Incluso si el muestreo de pared a pared está fragmentado (separado por intervalos no registrados o intervalos sin vetas), la clasificación automática de segmentos producirá resultados apropiados. Con las muestras de canal, si las muestras de vena se pueden incluir en el mismo canal continuo, perpendicular a la estructura de veta tabular, puede minimizar o eliminar la necesidad de ediciones manuales en Leapfrog Geo (figura 14).
Figura 14. Muestras de canales fragmentados. Las muestras de la izquierda deberán editarse manualmente para producir una triangulación de vena razonable, mientras que las muestras de la derecha funcionarán automáticamente
Fuente: Leapfrog Geo
🚀 Aprende sin límites
📚✨ Ahora todos nuestros cursos exclusivos están disponibles en YouTube Miembros y Patreon.
Únete hoy y accede a contenido avanzado, guías especializadas y soporte directo. 🎥🔥